Apr 12, 2026·History & Origins Of IQ Testing
The Past and Future of IQ Tests: 120 Years of Measuring Human Intelligence
From the Binet-Simon scale to modern AI and neuroimaging, explore the 120-year history of IQ tests and the future of measuring human intelligence.
IQ testing is one of the most consequential developments in the history of psychology. In just over a century, the field evolved from a primitive diagnostic tool into a global scientific instrument shaping decisions in schools, courts, militaries, and clinics — and the evolution is far from over. Advances in computerized adaptive testing, neuroimaging, and artificial intelligence are already reshaping what it means to measure the human mind. This article traces that journey from Galton's early missteps to the algorithms that may challenge the test entirely.
How Did Attempts to Measure Intelligence Begin?
Scientific interest in measuring intelligence began in the 1880s when Sir Francis Galton set up a laboratory in London and collected measurements on thousands of visitors: head circumference, grip strength, reaction time, visual acuity, and more. His hypothesis was that these physical and sensory traits would correlate with intelligence, which he assumed was linked to social class. The results were disappointing: he found no relationship between the variables he measured and social class. The ambition, however, was correct: intelligence is a real and measurable property, and scientific methods can approach it.
The real breakthrough came in 1905, when French psychologist Alfred Binet and his colleague Théodore Simon designed a test to identif which children in Paris were likely to struggle in regular classrooms and might benefit from individualized instruction. Their solution was the Binet-Simon Scale, widely regarded as the first modern intelligence test. Unlike Galton's physical measurements, the scale asked children to perform cognitive tasks, such as following simple directions, or naming differences between two common objects (such as wood and glass). The questions measured examinees’ ability to think and reason.
The interactive timeline below traces the major milestones in IQ test history from 1905 to the present.
How Did IQ Testing Spread — and How Was It Misused?
Stanford University's Lewis Terman revised and greatly expanded Binet's scale, publishing the Stanford-Binet in 1916. Terman believed intelligence was strongly hereditary and fixed, and he saw IQ testing as a tool for organizing society efficiently. Terman and other psychologists promoted intelligence tests as accurate, scientific, and valuable tools for bringing efficiency to schools and society.
A most dramatic expansion of testing occurred during World War I. The American Psychological Association (APA) established a committee of psychologists (including Terman) who created two group-administered tests: the Army Alpha for literate recruits and the Army Beta for illiterate ones. Over one million tests were administered before the war ended. The tests predicted training success and correlated with military rank — solid early evidence that IQ measured something real and meaningful outside the schoolhouse.
What Changed When David Wechsler Redesigned the Test?
By 1939, the Stanford-Binet had dominated American intelligence testing for two decades. David Wechsler, working at Bellevue Hospital in New York, thought it had fundamental problems: it was heavily verbal and better suited for children than adults. His Wechsler-Bellevue Intelligence Scale introduced two innovations that have defined professional IQ testing ever since.
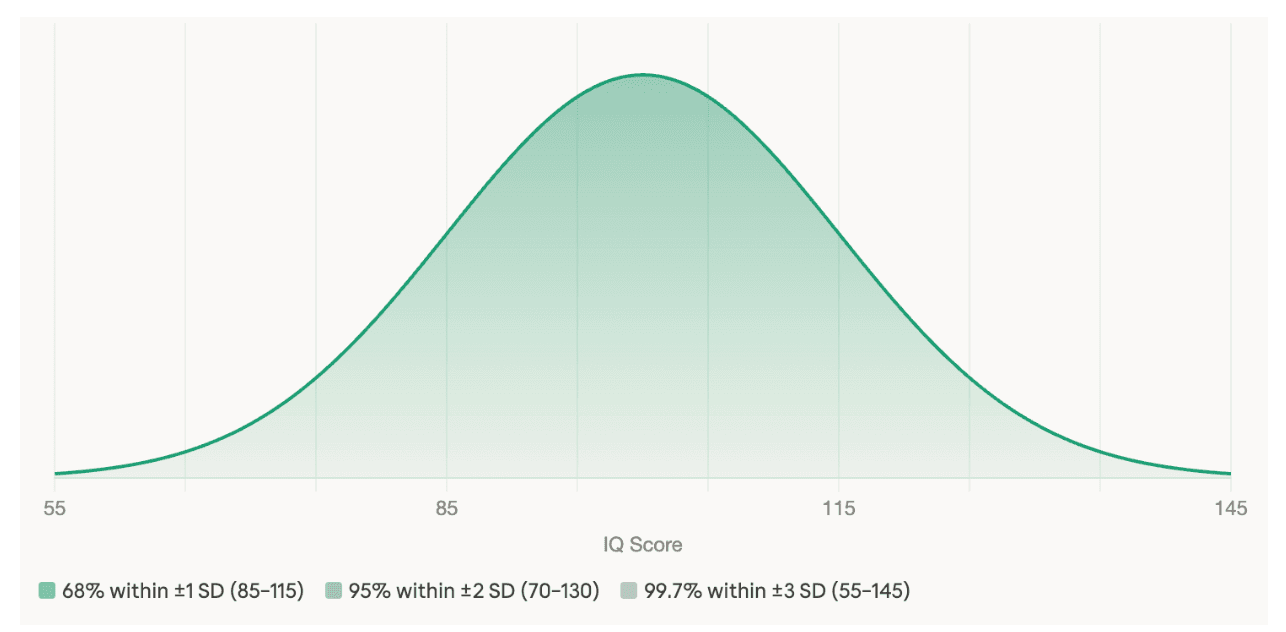
The first was the deviation IQ. Rather than expressing a score as a ratio of mental age to chronological age (the original "intelligence quotient"), Wechsler's method compared each person's performance to others in their own age group and expressed the result in standard deviation units. An IQ of 100 became the population average at any age, with each 15-point increment representing one standard deviation. This made adult testing far more interpretable and solved the problem that quotient IQs could not be meaningfully compared across ages. The second innovation was separating verbal and nonverbal performance into distinct scores, providing more clinical nuance than a single overall number could.
The chart below shows how IQ scores are distributed in the population under Wechsler's deviation scoring system — the system still used by every professional IQ test today.
What Is the Cattell-Horn-Carroll Theory and Why Does It Matter?
For much of the 20th century, intelligence researchers argued about whether intelligence was best described as a single general ability (often called “g”) or as a collection of distinct, independent mental faculties. That debate produced a proliferation of competing theories without clear resolution. The turning point came in 1993, when John B. Carroll published a synthesis of over 400 datasets and concluded that both camps had been partially right. General intelligence sits at the top of a hierarchy, but beneath it are a set of broad abilities — fluid reasoning, crystallized knowledge, spatial ability, processing speed, working memory, and others — each of which breaks down further into narrow, specific skills.
This hierarchical structure is called the Cattell-Horn-Carroll (CHC) theory, honoring Raymond Cattell and John Horn, who laid critical groundwork for the CHC theory. CHC theory is now the mainstream scientific framework for both intelligence research and test development. It gives a justification for modern professional tests to report both a global IQ score (measuring g) and a set of index scores covering distinct cognitive domains. A single number tells part of the story; a profile of scores tells a much richer one.
What Has the Public Always Gotten Wrong About IQ Tests?
Across the internet and decades of popular writing, the same misunderstandings surface with remarkable consistency. The most persistent is that IQ equals intelligence. It does not. IQ is a number produced by a test; intelligence is the underlying cognitive capacity that test is designed to measure. The relationship is the same as the one between temperature and heat: one is the measurement, the other is the phenomenon. This distinction matters practically because it explains why someone can improve their score on a retest without becoming more intelligent — they have learned the format of the test, not increased their underlying ability.
The second common error is treating IQ as deterministic. The research is clear that higher IQ is associated with better outcomes across education, occupational prestige, income, health, and longevity — but these are probabilistic tendencies, not guarantees. Some people with high IQs struggle; some with modest IQs thrive. Conscientiousness, social support, effort, and circumstance all interact with cognitive ability in ways that no single score can capture.
The third misconception, and perhaps the most commercially significant one, is that online IQ tests are equivalent to professionally developed assessments. The internet is flooded with tests designed to flatter users with inflated scores and encourage social sharing. These instruments lack norm samples, have no technical documentation, and are usually created by anonymous individuals with no training in test design. A professionally developed test requires years of research, pilot testing, expert review, and a representative norm sample drawn from the intended test population. That gap is not a matter of degree — it is categorical.
The Flynn Effect illustrates a related confusion. When James Flynn documented a roughly 3-point-per-decade rise in IQ test performance in the 1980s, some people thought that it indicated that human intelligence was rising dramatically — fast enough that people a few generations back would barely have functioned by modern standards. That interpretation, of course, is wrong. Research in the 21st century showed that the gains were concentrated in the non-g components of IQ tests: the specific skills that schools, media, and everyday life were increasingly training people to perform. Today, psychologists understand that the Flynn effect is merely a product of the alignment (or lack thereof) of the non-g skills society teaches and the test content. It also makes scores incomparable across generations, meaning it does not show that people are remarkably smarter than people were 100 years ago.
What Separates Modern Professional IQ Tests from Their Predecessors?
Three developments distinguish modern professional IQ testing from the tests of the mid-20th century: computerized and adaptive administration, item response theory scoring, and systematic bias screening.
Computerized administration began in the early 1980s and accelerated sharply during the COVID-19 pandemic, which forced many traditionally in-person assessments to move online or to video-based delivery. Beyond logistical convenience, computerized testing improves measurement quality — reaction times can be recorded to the millisecond, item presentation can be randomized, and test difficulty can adapt to each examinee in real time through computerized adaptive testing (CAT). CAT achieves the same measurement precision as a fixed-length test using roughly half as many items by continuously estimating ability and selecting the next question to provide maximum information at that estimated level.
Item response theory (IRT), developed from Georg Rasch's mathematical work and expanded by American psychometricians through the 1970s and 1980s, provided a more rigorous scoring framework than classical methods. IRT models the relationship between an examinee's ability and the probability of answering each item correctly, placing both items and people on the same scale and enabling test creators to build instruments that measure ability with known precision at every point along the scale.
Bias screening became standard in the 1960s in response to greater concern about the performance of diverse examinees on academic and intelligence tests. Today, methods of identifying bias have proliferated. Some of these are designed to identify bias in specific items (called differential item functioning), whereas others can detect bias of a total test score. Modern ethical standards dictate that items that show evidence of bias are revised or removed before publication and that total test scores with bias should not be used for cross-group comparisons or decisions. Today, professionally-designed modern IQ tests show no bias when administered to the populations they were designed for.
What Does the Future of IQ Testing Look Like?
The next generation of intelligence assessment is being shaped by converging developments in neuroimaging, artificial intelligence, and genetic prediction.
Can Brain Scans Predict Intelligence?
Perhaps the most striking recent development is progress in using neuroimaging to predict intelligence. Researchers have demonstrated that patterns of resting-state brain connectivity — measured with functional MRI while a person simply lies in a scanner doing nothing — can predict IQ scores with meaningful accuracy. A systematic review of 37 neuroimaging studies confirmed that resting-state functional connectivity is the strongest neuroimaging predictor of general intelligence and that the findings replicate reliably. Brain size, white matter connectivity efficiency, and neural activity entropy in the prefrontal cortex all correlate with IQ — establishing that g corresponds to something real in brain organization, not merely a statistical pattern in test responses.
The gap between laboratory measurement and clinical application remains wide, though. fMRI is expensive, time-consuming, and requires specialized facilities. For the foreseeable future, behavioral IQ tests remain far more practical for assessing the populations that need assessment most.
What Role Will AI Play?
Artificial intelligence is intersecting with IQ testing in two distinct ways. The first is as a tool for improving how human intelligence is assessed. Machine learning models can detect subtle item interactions across large response datasets, identify careless responding, flag potential bias, and personalize the testing experience in ways that were previously impossible. These are genuine improvements to the psychometric toolkit.
The second intersection is more philosophically complex: researchers have been attempting to measure the "intelligence" of AI systems using adapted versions of human IQ tests. IBM Research reported a neuro-vector-symbolic AI model capable of solving Raven's Progressive Matrices — a classic IQ format — with an 88% success rate, surpassing average human test-taker performance. More recently, a 2024 study an administration of a computerized adaptive vocabulary test to GPT-3.5 and Bing (based on GPT-4), finding that both outperformed average human test takers on verbal items.
These results are interesting but require careful interpretation. Language models trained on enormous text corpora will naturally perform well on vocabulary subtests — that reflects their training, not a generalizable reasoning capacity. More fundamentally, IQ tests were designed for human cognition and their scales do not straightforwardly apply to non-human architectures. Human IQ is normed on human populations with human brains; applying those norms to systems that process information through matrix multiplication across billions of parameters creates comparisons that are genuinely difficult to interpret. The question of how to measure artificial intelligence meaningfully is one of the most active and unresolved debates in the field today.
What About Genetic Prediction of Intelligence?
A third emerging frontier is polygenic scoring — combining hundreds or thousands of DNA variants to predict cognitive outcomes. There are now hundreds of identified genetic variants associated with IQ differences, and polygenic scores built from them can predict IQ with modest but statistically meaningful accuracy that is expected to improve as datasets grow larger.
Genetic predictions will not replace behavioral IQ tests. Genes set developmental probabilities, not outcomes. A polygenic score predicts average cognitive outcomes across populations with similar genotypes; it says almost nothing definitive about any given individual. The behavioral test — measuring what a person actually does with their cognitive capacity right now — will remain the most directly useful instrument for individual assessment. What genetic research contributes is a deeper understanding of intelligence's biological architecture and, eventually, a tool for identifying children most likely to benefit from early cognitive enrichment.
How Will Tests Change in Form?
Looking at the past 50 years, the direction is clear: the testing industry will continue to embrace technology, not just in administration but in the data that are used to measure intelligence. None of that changes the psychometric foundation required to make those scores trustworthy. A test still needs a representative norm sample, documented reliability and validity evidence, theory-grounded design, and expert authorship with professional accountability. Technology makes administration more convenient and scores more precise, but it cannot substitute for the scientific rigor that separates a legitimate instrument from a consumer app.
Take the First Professional Online IQ Test
The Reasoning and Intelligence Online Test (RIOT) is the first online IQ test built to meet the same professional standards as traditional individually-administered assessments. Developed after 15 years of active intelligence research, built on the Cattell-Horn-Carroll theory, normed on a representative U.S. sample, and designed to meet the Standards for Educational and Psychological Testing published by the American Educational Association, APA, and National Council on Measurement Education, the RIOT provides a global IQ score alongside index scores for Verbal Reasoning, Fluid Reasoning, Spatial Ability, Working Memory, Processing Speed, and Reaction Time — a detailed picture of cognitive functioning that a single number never could.
Citations
Flynn, J. R. (1984). The mean IQ of Americans: Massive gains 1932 to 1978. Psychological Bulletin, 95(1), 29–51. https://doi.org/10.1037/0033-2909.95.1.29
Carroll, J. B. (1993). Human cognitive abilities: A survey of factor-analytic studies. Cambridge University Press. https://doi.org/10.1017/9781108593298
Gottfredson, L. S., et al. (1997). Mainstream science on intelligence. Intelligence, 24(1), 13–23. https://doi.org/10.1016/S0160-2896(97)90011-8
Plomin, R., & von Stumm, S. (2018). The new genetics of intelligence. Nature Reviews Genetics, 19, 148–159. https://doi.org/10.1038/s41588-018-0152-6
Ritchie, S. J., et al. (2018). How much does education improve intelligence? Psychological Science, 29(8), 1358–1369. https://doi.org/10.1177/0956797618774253
Warne, R. T. (2025). Technical manual for the Reasoning and Intelligence Online Test, version 1.0. RIOT IQ.
Dubois, J., et al. (2018). A distributed brain network predicts general intelligence from resting-state human neuroimaging data. Philosophical Transactions of the Royal Society B. https://www.caltech.edu/about/news/caltech-scientists-can-predict-intelligence-brain-scans-82675
Kovacs, K., & Klein, B. (2024). The performance of ChatGPT and Bing on a computerized adaptive test of verbal intelligence. PLOS ONE. https://pmc.ncbi.nlm.nih.gov/articles/PMC11271876/
Bratsberg, B., & Rogeberg, O. (2018). Flynn effect and its reversal are both environmentally caused. PNAS, 115(26), 6674–6678. https://doi.org/10.1073/pnas.1718793115
Deary, I. J., et al. (2021). Genetic contributions to self-reported tiredness. Molecular Psychiatry. https://doi.org/10.1037/a0035893
Murray, C. (2002). IQ and income inequality in a sample of sibling pairs from advantaged family backgrounds. American Economic Review, 92(2), 339–343. https://doi.org/10.1257/000282802320191570
Penrose, L. S., & Raven, J. C. (1936). A new series of perceptual tests. British Journal of Medical Psychology, 16(2), 97–104. https://doi.org/10.1111/j.2044-8341.1936.tb00690.x
IBM Research. (2022). Neuro-vector-symbolic AI solves Raven's matrices. https://research.ibm.com/blog/neuro-vector-symbolic-architecture-IQ-test
Warne, R. T., & Burningham, C. (2019). Spearman's g found in 31 non-Western nations. Psychological Bulletin, 145(3), 237–272. https://doi.org/10.1037/bul0000184
Gignac, G. E., & Bates, T. C. (2017). Brain volume and intelligence. Intelligence, 64, 18–29. https://doi.org/10.1016/j.intell.2019.01.011
Sniekers, S., et al. (2017). Genome-wide association meta-analysis of 78,308 individuals. Nature Genetics, 49, 1107–1112. https://doi.org/10.1038/ng.3869
Moore, T. M., et al. (2019). Development of the Penn Reading Assessment Computerized Adaptive Test for premorbid IQ. Neuropsychology, 33(6). https://pubmed.ncbi.nlm.nih.gov/31192630/
Iliescu, D., et al. (2022). Prediction of intelligence from neuroimaging: A systematic review. Intelligence, 92. https://www.sciencedirect.com/science/article/pii/S0160289622000356
Take our professional IQ test
Want to know your IQ? Try the first ever professional online IQ test.
Article Categories
All ArticlesUnderstanding IQ ScoresTaking an IQ TestRIOT-Specific InformationGeneral IQ & IntelligenceAdvanced Topics & ResearchIQ Scores & InterpretationMensa & High-IQ SocietiesOnline IQ Tests IQ Test Basics & FundamentalsAverage IQ & DemographicsFamous People & IQHistory & Origins Of IQ TestingAccuracy, Reliability & CriticismSpecial Population & Related ConditionsImproving IQ / PreparationSpecific IQ Tests & FormatsIQ Testing for HR & RecruitmentSkills Assessment
Related Articles
The Evolution of IQ Testing: A Historical PerspectiveIQ Tests: Understanding the ControversiesThe Role of IQ Tests in Education and Career AssessmentTop 10 Facts About IQ Tests Everyone Should KnowThe Past and Future of IQ Tests: 120 Years of Measuring Human IntelligenceHow Old Are IQ Tests?How is IQ Measured or Calculated?Why Were IQ Tests CreatedDo Schools Test For IQ?How Are IQ Tests CreatedWhen Was IQ Testing Invented?How Do IQ Tests Work?Who Invented the IQ Test?
Take our IQ testsCompare all tests
Basic IQ Test
5 subtests + 5 cognitive abilities
Features
- ~13 Minutes
- IQ score
- Cognitive abilities breakdown
- ±5.6 IQ margin of error
5/15 Subtests
Learn moreVocabulary
Matrix Reasoning
SToVeS
Visual Reversal
Symbol Search
Full IQ Test
15 subtests + all cognitive abilities
Features
- ~52 Minutes
- IQ score
- Cognitive abilities breakdown
- ±3.7 IQ margin of error
15/15 Subtests
Learn moreVocabulary, Information, Analogies
Matrix Reasoning, Visual Puzzles, Figure Weights
Object Rotation, SToVeS, Spatial Orientation
Computation Span, Exposure Memory, Visual Reversal
Symbol Search, Abstract Matching
Simple Reaction Time, Choice Reaction Time
Community
Intelligence Journals & Organizations
News & Press
Our Articles
Our Articles
Our Articles
Our Articles
Our Articles