Are IQ tests culturally biased? Explore the science behind stereotype threat, the Flynn effect, and group differences. Read the guide and take the RIOT!
Few scientific instruments generate as much heat as IQ tests. In over a century of research, psychologists have learned an enormous amount about human intelligence. At the same time, IQ testing has attracted serious criticism—some of it well-founded, some of it based on misunderstandings of what the tests are actually measuring. After spending more than 15 years studying intelligence and creating an IQ test myself, I have found that the controversies surrounding IQ tests are often more complicated than the popular discourse suggests. Most critiques reveal something important about the limits of IQ testing. But most do not actually support the conclusion that IQ tests are worthless or that intelligence research should be abandoned.
This article unpacks the major controversies in IQ testing. The goal is not to defend IQ tests uncritically, but to apply the same standard of evidence to the criticisms that psychologists apply to the tests themselves.
Are IQ Tests Biased?
This is probably the most common criticism directed at IQ tests. The charge is that IQ tests systematically disadvantage certain racial, ethnic, or socioeconomic groups—not because those groups are less intelligent, but because the tests are constructed in ways that favor people from majority cultural backgrounds.
The concern is not irrational. Early IQ tests were sometimes deliberately constructed by people with racist assumptions. Lewis Terman, who adapted the Binet test for use in the United States, believed his test confirmed the intellectual inferiority of certain immigrant groups and people of African descent. He did not hide this view; he published it openly. That history is real, and it has understandably left a lasting distrust of intelligence testing in many communities.
The more important question, though, is whether modern IQ tests are still biased in the technical sense. Psychologists distinguish carefully between two related but distinct concepts: test bias and test fairness. Bias, in the technical sense, occurs when a test systematically over- or underpredicts outcomes for a specific group for reasons unrelated to the trait being measured. Test fairness is a broader social question about whether the use of a test leads to equitable outcomes across groups. An unbiased test can still produce unfair results if used in the wrong context or population—these are related but distinct concerns.
Take our professional IQ test
Want to know your IQ? Try the first ever professional online IQ test.
Since the 1960s, and especially since the 1980s, professionally developed IQ tests have been systematically screened for biased content before release.This process involves statistical techniques that identify whether specific test items function differently across groups, even if overall score differences remain. Items that show differential functioning unrelated to the trait being measured are revised or removed. Across decades of studies, mainstream professionally developed IQ tests do not predict differently for different racial or socioeconomic groups within the United States—meaning the test predicts academic performance, occupational outcomes, and other criteria at essentially the same rate regardless of group membership.
It is worth being precise about what this finding does not mean. An unbiased test can still produce average score differences between groups. The existence of group differences raises legitimate questions about environmental influences on cognitive development, and the research on bias does not resolve those questions. It simply tells us that the differences observed in IQ scores are not artifacts of the measurement instrument itself.
What Does the Controversy Over Group Differences Actually Involve?
Average group differences in IQ scores are among the most well-documented and most misunderstood findings in all of psychology. The findings themselves are not in dispute. East Asian groups tend to score slightly higher on average than groups of European descent in the United States, and groups of African descent score lower on average than groups of European descent. The Black-White IQ gap in the United States has typically been reported at between 10 and 15 points, though it hasnarrowed somewhat over the past several decades.
The controversy is not whether these differences exist. The controversy is about their causes. Two broad positions have dominated this debate for over 50 years.
The environmentalist position holds that group differences in IQ are entirely a product of environmental factors: differences in educational quality, socioeconomic resources, exposure to environmental toxins like lead, test-taking experience, and the cumulative effects of historical discrimination. The hereditarian position holds that genetic factors contribute to some portion of the between-group difference, given that the heritability of IQ within populations is substantial and that within-group heritability places mathematical constraints on the plausibility of purely environmental explanations.
The current scientific consensus, as confirmed by analyses of polygenic scores from the 1000 Genomes Project, is thatgenetics does not explain differences in IQ test performance between racial groups. Environmental factors are the most plausible explanation for the observed gaps—and the historical narrowing of the Black-White gap over the second half of the 20th century is consistent with that position, since improving environments should narrow a gap that is environmentally driven.
The deeper problem with this debate is that it is sometimes weaponized. Those who want to deny the reality of intelligence differences entirely distort the science in one direction; those who want to draw sweeping heritability conclusions distort it in another. Psychologists who study intelligence are not, by and large, ideologically motivated—they are trying to understand a complex set of findings, and responsible science requires acknowledging both what is known and what is not.
Does Stereotype Threat Explain IQ Score Gaps?
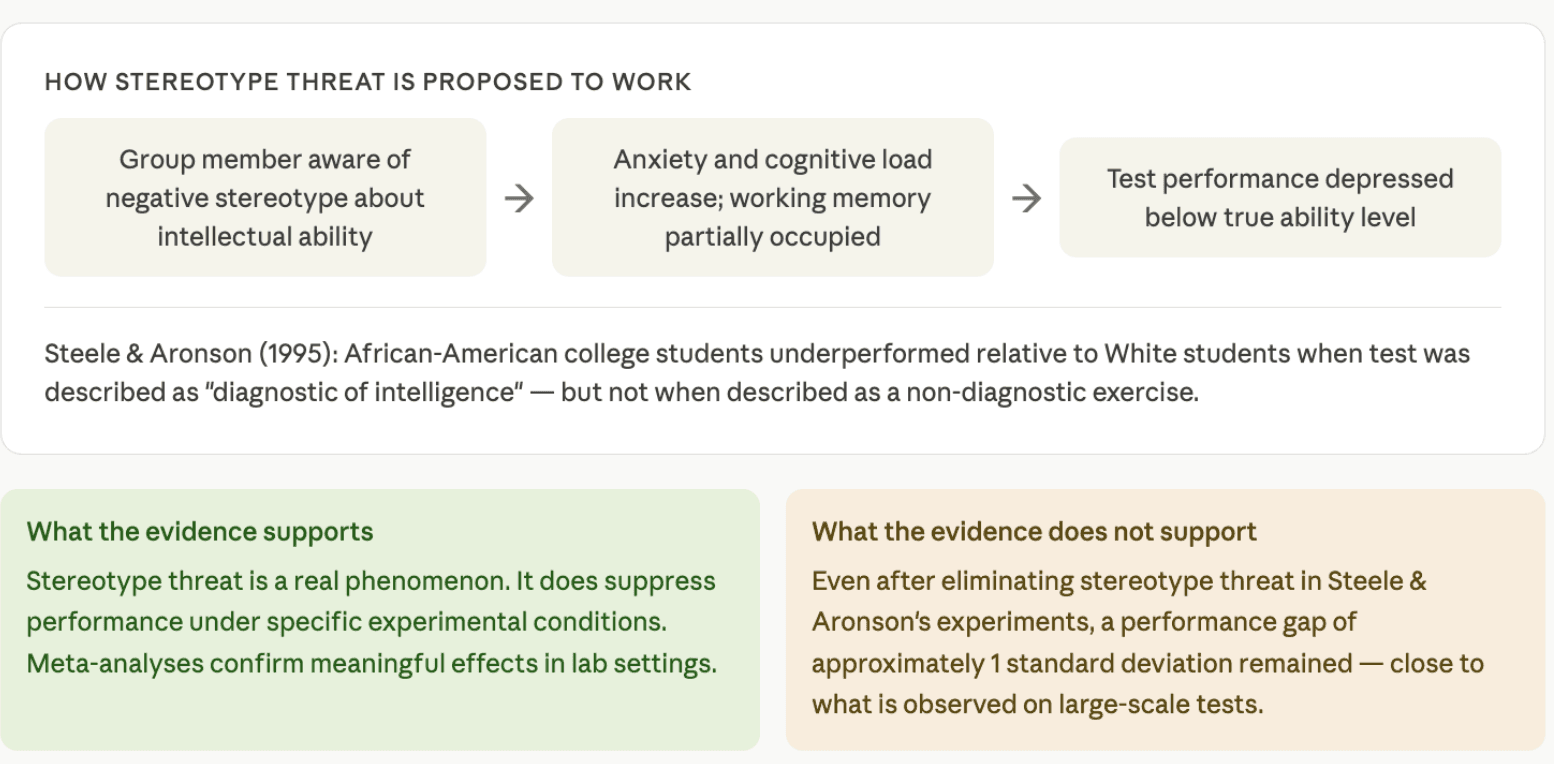
One of the most widely cited explanations for group score differences is "stereotype threat"—a psychological phenomenon first described by Claude Steele and Joshua Aronson ina landmark 1995 study. The idea is that when members of a group know they belong to a group negatively stereotyped in an academic domain, that awareness creates psychological pressure that impairs their test performance—not because of lower ability, but because cognitive resources are redirected toward managing the threat.
The original finding was compelling: Black college students who were told a verbal test was diagnostic of intelligence performed worse relative to White students than Black students who were told the same test was a non-diagnostic problem-solving exercise.
However, a major misinterpretation of this finding has been widely repeated in both journal articles and textbooks. Many accounts claimed that removing stereotype threat eliminated the Black-White performance gap entirely. Paul Sackett and colleaguesshowed in 2004 that even in the low-threat condition, a gap of approximately one standard deviation remained—and Steele and Aronson themselves confirmed this interpretation in subsequent correspondence. The misinterpretation did not originate with the original researchers; it was introduced by others who cited the study without reading it carefully.
Stereotype threat almost certainly contributes something to performance gaps in high-stakes testing situations. But its contribution is modest, and using it to dismiss the score differences entirely is not warranted.
Does High Heritability Mean IQ Is Fixed?
Studies using twin, adoption, and family data consistently find that intelligence is substantially heritable—meaning that a meaningful proportion of the variation in IQ scores among individuals in a given population can be attributed to genetic differences. In adults living in wealthy countries, heritability estimates generally range from about 0.50 to 0.80.
Critics sometimes interpret high heritability as evidence that IQ is fixed and cannot be changed. This reflects a fundamental misunderstanding of what heritability actually measures.
Heritability is not a property of intelligence itself. It is a property of a specific population in a specific environment. It tells you how much of the variation in IQ within that population, at that time, is associated with genetic differences, given the range of environments that population was exposed to. Change the environment dramatically enough, and heritability changes too. A population of clones would have zero heritability for IQ because there are no genetic differences to produce variation; a population where everyone had an identical environment would have heritability of 1.0 because no environmental differences would remain to cause any variation.
The correct interpretation of high heritability in a population is this: given the range of environments that the population was exposed to, genetic variation explained more of the differences in IQ than environmental variation did. That finding coexists comfortably with the fact that improving environments can and do raise IQ.
Are IQ Tests Culturally Biased Against Non-Western Populations?
The cultural bias critique takes a different form when applied across national or cultural boundaries. The concern is that IQ tests developed by Western psychologists assume a particular kind of schooling, familiarity with abstract reasoning tasks, and cultural knowledge that is not universal. When administered in a country with a very different educational and cultural context, a test may not be measuring the same thing it measures in its country of origin.
This concern has more empirical support than the domestic bias critique. Research has shown that when tests like the Raven's Progressive Matrices are administered in countries with limited formal schooling and little experience with standardized testing, the scores often do not predict outcomes in the same way they do in the countries where the tests were developed. The concepts that culture-reduced tests rely on—geometric shapes, patterns, the format of a multiple-choice item itself—are still culturally loaded in subtle ways that disadvantage examinees with limited exposure to abstract test-taking conventions.
This is not a failure of the test design per se; it is a failure to match the test to its intended population. Professional IQ test creators are clear about who their tests are designed for and explicitly caution against using them outside of target populations without first gathering validity evidence. The appropriate response to this problem is to be careful about the scope of inferences drawn from scores when tests are used in populations they were not designed for—a limitation that responsible psychologists acknowledge openly.
Does the Flynn Effect Mean IQ Tests Are Invalid?
The Flynn effect—the well-documented rise in average IQ test performance across the 20th century, approximately 3 points per decade—has been used by some critics to argue that IQ tests cannot be measuring real intelligence. If average intelligence has been rising so dramatically, the argument goes, then either our ancestors were cognitively impaired, or the tests are not measuring actual intelligence.
Neither conclusion is correct. The Flynn effect operates primarily on the non-g components of IQ, not on general intelligence itself. Changes in education, greater familiarity with abstract testing formats, improved nutrition, and other environmental changes raised performance on specific subtests without necessarily raising the core general ability that IQ tests are designed to measure. IQ scores are relative measures—they describe where a person falls in the distribution of their contemporaries. The Flynn effect simply means that those contemporaries, on average, score differently across generations. Knowing this, psychologists periodically re-norm IQ tests to account for changing average performance levels. This is standard practice and does not represent a flaw in the measurement approach. What the Flynn effect actually demonstrates is that environmental factors can and do raise IQ test performance over time—which is entirely consistent with what research on schooling, nutrition, and adoption has shown.
Are IQ Tests a Fair Predictor of Life Outcomes—Or Do They Just Measure Test-Taking Ability?
A related criticism is that IQ tests do not measure genuine intelligence at all—that they simply measure how good someone is at taking tests. This is a reasonable concern on its face. IQ scores do improve with retesting (practice effects account for roughly 5 points on a second administration), and learning item-specific strategies can raise scores temporarily on specific subtests.
These are real effects. But they do not come close to explaining away the validity of IQ tests. If IQ scores merely reflected test-taking experience, they would not predict outcomes in settings that have nothing to do with test performance. In reality, IQ scores predict job training success, on-the-job performance, educational achievement, income, health outcomes, and longevity at rates that areamong the most replicated findings in the social sciences. These predictions hold up even in populations with minimal formal testing experience.
The more substantive version of this critique is that IQ tests capture only certain kinds of reasoning—the kinds emphasized in Western academic settings—and therefore give an incomplete picture of cognitive ability. This is true, and it is acknowledged openly by professional IQ test developers. No single test can measure everything. The CHC (Cattell-Horn-Carroll) theory that underlies most modern IQ tests explicitly recognizes multiple distinct cognitive abilities beyond a single g factor. That is why tests built on this framework report both a global IQ and specific subscores for abilities like fluid reasoning, working memory, processing speed, and verbal ability. The global score is a useful summary; the subscores add nuance that a single number cannot provide.
Has Intelligence Research Been Tainted by Its History?
This is perhaps the most philosophically complex controversy. The history of IQ testing includes genuinely shameful episodes. Early 20th-century psychologists used IQ test results to argue for restrictive immigration policies, to justify forced sterilization programs, and to reinforce existing racial hierarchies. The eugenics movement drew extensively on intelligence research, and several prominent early researchers held views that are rightfully condemned today.
The honest answer is: this history should make researchers more vigilant, not less rigorous. The appropriate response to a history of misuse is not to abandon the measurement of intelligence, but to apply more careful standards to both the research and its applications. Modern intelligence research is held to these standards. Professionally developed IQ tests are screened for bias. Their developers are transparent about the populations they are designed for and the purposes their scores are valid for. The major professional organizations in psychology have published explicit ethical guidelines governing the use of test scores.
Genetics was also misused in the service of eugenics. That did not make genetics invalid as a scientific discipline—it made the misuse of genetic data unethical. The same principle applies to intelligence research. The history of abuse is a reason for ongoing ethical vigilance; it is not evidence that intelligence cannot be measured or that IQ scores have no valid uses.
The Controversy Over Intelligence Theories
One last source of controversy involves not the tests themselves, but the theories of intelligence that underlie them. Critics argue that psychologists have not agreed on what intelligence actually is, and that without a settled theory, the tests are measuring something undefined.
It is true that there is no single universally accepted theory of intelligence. Howard Gardner's theory of multiple intelligences and Robert Sternberg's triarchic theory each proposed alternatives to the mainstream view. However, as covered in earlier articles in this series, neither theory has fared well against the empirical evidence. Gardner's core claim—that the intelligences are independent of one another—is contradicted by the consistent finding that cognitive abilities intercorrelate positively. Sternberg's theory has faced serious challenges in establishing that the components he proposed are actually distinct and measurable. The CHC theory is not a perfect theory—psychologists continue to debate the exact number of cognitive abilities in the hierarchy and the precise relationships among them. But it is by far the best-supported theory of intelligence available, grounded in a massive empirical literature accumulated over more than a century. The fact that theoretical debates continue is not unusual in science. It does not mean that the underlying measurement is uninformative. It means the science is ongoing—and that the tools for measuring intelligence, while imperfect, are among the most validated instruments in all of psychology.
What the Controversies Actually Tell Us
Taken together, the major controversies in IQ testing point in the same direction. Professionally developed tests, used on the populations they were designed for, are not biased in the technical sense. The causes of group score differences are genuinely unresolved—environmental explanations are better supported than genetic ones, but the science is complex and honest researchers acknowledge what is not yet known. And the history of abuse in intelligence testing is real, but it is a call for ongoing ethical vigilance, not for abandoning measurement altogether.
Intelligence research has generated more carefully replicated findings than almost any other area in psychology. The controversies around IQ tests deserve serious engagement—and serious engagement means applying the same standards of evidence to the critiques that are applied to the findings themselves.
Professional Online IQ Testing
For anyone interested in obtaining a reliable, professionally developed IQ score, the test matters as much as the results. Most online IQ tests are created by individuals with no formal training in psychometrics and no accountability for the quality of their instruments. They produce scores with no established reliability, no representative norm sample, and no validity evidence.
TheReasoning and Intelligence Online Test (RIOT) was built to a different standard. It is the first professionally developed online IQ test—created with the same rigor applied to traditional tests used by psychologists in clinical and educational settings. The RIOT was developed after more than 15 years of intelligence research, reviewed by a panel of experts from cognitive, educational, and developmental psychology, normed on a representative U.S. sample, and built to meet the standards for educational and psychological testing established by the APA, AERA, and NCME. It reports both a global IQ and subscores across multiple cognitive abilities, providing the kind of detailed profile that a single number cannot capture.
The controversies described in this article are reasons to be thoughtful about how IQ tests are developed and used—not reasons to avoid professionally developed tests altogether.
Sources
Warne, R. T. (2025). Technical manual for the Reasoning and Intelligence Online Test, version 1.0. Riot IQ.