Jun 10, 2026·History & Origins Of IQ Testing
The Evolution of IQ Testing: A Historical Perspective
Discover the history of IQ testing, from early experiments to modern psychometrics. Read the full timeline and try the professional RIOT IQ test today!
When most people think of an IQ test, they picture a generic quiz on a website that spits out a number in seconds. That is not what IQ testing actually is. A professionally developed IQ test is a scientific instrument built to measure one of the most complex and consequential attributes a person has: their general cognitive ability. Understanding where IQ tests came from matters, because the choices made by early researchers shaped the tools we still use today. Some of those choices were brilliant. Others were deeply problematic. Both deserve honest accounting.
I have spent most of my career studying intelligence and its measurement. The more I have examined the history of this field, the more I appreciate that modern IQ testing is not a product of any single genius — it is a cumulative achievement built on layers of correction, revision, and refinement. This article traces that evolution from the earliest attempts to quantify the mind through to the contemporary instruments that now define professional cognitive assessment.
What did the 19th century get right — and wrong?
The scientific ambition to measure human intelligence predates the 20th century by decades. Sir Francis Galton — a Victorian polymath and cousin of Charles Darwin — was among the first to take the project seriously. In 1884, he established an anthropometric laboratory in London where visitors paid a small fee to have their physical and sensory characteristics measured: reaction time, visual acuity, grip strength, auditory discrimination, and more. By the time the laboratory closed, data had been collected on more than 17,000 individuals.
Galton's hypothesis was that intelligence could be assessed through sensory efficiency. He reasoned that people who perceived the world more sharply and responded to stimuli more quickly must have superior cognitive machinery. The hypothesis was plausible, and the ambition behind it was genuinely scientific. The problem was that the data did not support it. The correlations between sensory measures and any recognizable indicator of intellectual ability were negligible. Galton's methods were not sensitive enough to detect the real relationship, and some of the variables he measured — grip strength, for instance — have no meaningful relationship with intelligence at all.
The larger lesson, though, is that Galton's work was not entirely wrong. He was right that intelligence could in principle be measured, right that individual differences in cognitive ability were real and worth studying, and right that reaction time has some relationship with mental ability — a relationship that modern research has confirmed, though it is modest. More importantly, Galton invented the statistical tools — correlation and regression to the mean — that every intelligence researcher since has depended on. The father of psychometrics got the measurement wrong but gave the field the mathematics it needed to do better.
His ideas were carried forward into America by James McKeen Cattell, who published a series of "mental tests" in the 1890s based on similar sensory and reaction-time measures. Those tests also failed to predict anything useful about academic performance. The sensory approach was eventually abandoned, but it marked a necessary dead end — the field had to learn what intelligence was not before it could properly measure what it was.
Alfred Binet and the cognitive revolution
The decisive break came in France. Alfred Binet had been following developments in intelligence research closely, and he was dissatisfied with the sensory approach for the same reasons the data eventually showed it to be inadequate. Binet believed that intelligence was not a matter of sensory acuity — it was a matter of higher-order cognitive processes: attention, judgment, memory, comprehension, and reasoning.
In 1904, the French government commissioned Binet and his colleague Théodore Simon to develop a method for identifying children who were likely to struggle in regular classrooms and might benefit from individualized instruction. Their response, published in 1905, was the Binet-Simon Scale — a set of 30 tasks arranged in order of increasing difficulty, ranging from simple tasks that most young children could complete to more complex ones that only older or more capable children could handle. It was the world's first practical intelligence test.
The scale was revised in 1908, when Binet introduced one of his most enduring contributions: the concept of mental age. A child's performance was expressed in terms of the age at which typical children achieved the same results. A child who solved tasks typical of seven-year-olds had a mental age of seven, regardless of their actual chronological age. Children whose mental age lagged their chronological age were identified as candidates for additional educational support.
One thing worth noting about Binet is that he was deeply cautious about his own instrument. He explicitly warned against treating the scale as a fixed measure of innate, immutable intelligence. He believed that the cognitive abilities it captured were malleable and could be improved with appropriate intervention. That caution was ignored by many of those who built on his work — with consequences that would follow intelligence testing for decades.
The timeline below marks the key milestones from Galton's laboratory to the Binet-Simon Scale:

The Stanford-Binet and the arrival of IQ in America
Binet's scale crossed the Atlantic almost immediately. Stanford University psychologist Lewis Terman revised and greatly expanded the test for use in the United States, publishing the Stanford-Binet Intelligence Scale in 1916. Terman adopted the formula proposed by the German psychologist William Stern, who had coined the term Intelligenz-Quotient in 1912: divide the child's mental age by their chronological age and multiply by 100. A child performing exactly at the level expected for their age would score 100. One performing above that level would score above 100.
The Stanford-Binet was wildly successful. It quickly became the dominant intelligence test in the United States and remained so for decades. It was adapted, translated, and refined through multiple editions, and a modern version — the Stanford-Binet 5 — is still in clinical use today.
Terman's contribution was real and consequential. But his views on what intelligence testing implied were more troubling. Terman was a committed hereditarian who believed that IQ scores reflected fixed, innate intellectual capacity — a position he held with considerably more certainty than the evidence warranted. He was also deeply involved in the eugenics movement, and he used intelligence test data to advocate for policies that would have — and in some cases did — cause serious harm. This aspect of Terman's legacy is important to understand, not because it invalidates the measurement instrument he helped develop, but because it illustrates what happens when scientific findings are applied with more ideological confidence than empirical warrant.
World War I and the birth of group testing
The entry of the United States into World War I in 1917 created an urgent practical problem: nearly two million military recruits needed to be assessed and classified quickly. Individual testing of that scale was impossible. Robert Yerkes, then president of the American Psychological Association, organized a committee of psychologists — including Terman — to develop group intelligence tests that could be administered simultaneously to large numbers of men.
The result was two tests. The Army Alpha was a written examination for literate recruits, covering analogies, number sequences, and general knowledge. The Army Beta was a pictorial, non-verbal test designed for illiterate recruits or those who did not speak English. By the time testing ended, over 1.7 million men had been assessed — the first large-scale intelligence testing program in history.
The Army tests were an important proof of concept. They demonstrated that intelligence could be measured in group settings, that the scores predicted outcomes like training performance and officer selection, and that mass testing was administratively feasible. These were genuine achievements that expanded what the field understood about intelligence assessment.
But the Army testing program also became entangled with the eugenics movement in ways that had serious consequences. Yerkes and several colleagues used the Army data to argue — with far more confidence than the evidence supported — that the intelligence of different racial and national groups varied in ways that had hereditary origins. These claims were used to support restrictive immigration legislation that passed in 1924, severely limiting immigration from Southern and Eastern Europe and other regions. The misuse of intelligence test data to justify discriminatory policy is one of the most troubling chapters in the history of psychology, and it casts a long shadow.
The lesson is not that intelligence tests cannot be used to compare groups — they can, with appropriate methodology and honest acknowledgment of complexity. The lesson is that science becomes dangerous when findings are over-interpreted to serve ideological ends, and when researchers fail to distinguish between what their data actually shows and what they want it to show.
David Wechsler and the deviation IQ
By 1939, the Stanford-Binet had dominated American intelligence testing for more than two decades. David Wechsler, a clinical psychologist working at Bellevue Hospital in New York, believed it had fundamental problems. It was heavily verbal, relied on items designed primarily for children, and still used the ratio IQ formula — which had a well-known flaw: it broke down completely for adults. Because cognitive growth does not continue indefinitely with age, there is no sensible way to calculate a "mental age" for a 45-year-old the way one can for a 10-year-old. Setting every adult's chronological age to 16 for calculation purposes, as was sometimes done, was an unsatisfying workaround.
Wechsler's 1939 Wechsler-Bellevue Intelligence Scale introduced two changes that have defined professional IQ testing ever since. First, it was explicitly designed for adults, with tasks and difficulty levels appropriate for the adult age range. Second, it replaced the ratio IQ with what is now called the deviation IQ. Rather than dividing mental age by chronological age, Wechsler compared each person's performance to that of others in the same age group and expressed the result in standard deviation units. The average was set at 100, with each standard deviation corresponding to 15 points. This system solved the adult testing problem, made scores comparable across age groups, and provided a statistical framework that is standard in every professional IQ test produced since.
Wechsler also introduced separate verbal and performance IQs alongside a full-scale score — an early acknowledgment that a single number, however useful, does not capture the full picture of an individual's cognitive profile. That instinct was sound, and it anticipated the later development of index scores and broad ability scores that are now standard in cognitive batteries.
The graphic below shows how the major scoring approaches evolved across the history of IQ testing:

The mid-20th century: proliferation and the bias debate
The decades following Wechsler's work saw rapid growth in IQ testing across educational, clinical, and research settings. The Wechsler scales expanded to cover children — the Wechsler Intelligence Scale for Children appeared in 1949 — and modern versions of the WAIS, WISC, and WPPSI are still the most widely used individually administered IQ tests in the world. The Raven's Progressive Matrices, published by John C. Raven in 1938, offered a non-verbal alternative and became one of the most widely used single-format tests in cross-cultural research.
As IQ testing became more widespread, it also became more scrutinized. By the 1960s, psychologists and civil rights advocates were raising serious questions about whether IQ tests were biased against minority groups and people from lower socioeconomic backgrounds. These were legitimate questions that the field was right to take seriously. The debate led to an important body of research on the statistical definition and detection of test bias, and it eventually changed how IQ tests were built.
The research findings were, and remain, more nuanced than popular discourse typically acknowledges. Tests can show average score differences between groups without being biased in the technical sense — bias occurs when a test systematically underestimates or overestimates the ability of members of a particular group for reasons unrelated to the construct being measured. Investigators who studied this question found that modern IQ tests, developed after the 1960s, are not biased for the groups they are designed for, though tests used outside their intended populations can show bias. As a result of the bias research, item screening became standard practice. Before a test is released today, its items are reviewed by diverse panels of experts and subjected to statistical analysis to identify and remove any content that functions differently across demographic groups. This is now a baseline requirement for professional test development, not an afterthought.
Carroll, CHC theory, and the modern theoretical framework
For much of the 20th century, intelligence researchers were divided on a fundamental question: is intelligence one thing or many things? Charles Spearman's discovery of the general factor g in 1904 suggested one answer. Louis Thurstone's identification of seven primary mental abilities in the 1930s suggested another. For decades, these positions competed without resolution. Howard Gardner's theory of multiple intelligences and Robert Sternberg's triarchic theory, both published in the 1980s, added more competing frameworks without resolving the debate.
The turning point came in 1993, when John B. Carroll published an extraordinary synthesis: Human Cognitive Abilities: A Survey of Factor-Analytic Studies. Carroll reanalyzed more than 460 datasets collected over decades of intelligence research and found that both Spearman and Thurstone had been partially right. General intelligence (g) sits at the top of a hierarchy, but beneath it are a set of broad abilities — fluid reasoning, crystallized intelligence, spatial ability, processing speed, working memory, long-term retrieval, and others — each of which breaks down further into narrow, specific skills. Neither g alone nor a collection of independent abilities told the complete story; the truth was a structured hierarchy.
Carroll's three-stratum model was subsequently integrated with the earlier Cattell-Horn model of fluid and crystallized intelligence to produce what is now called the Cattell-Horn-Carroll (CHC) theory. This became — and remains — the dominant theoretical framework in intelligence research. Most major IQ tests developed since the 1990s, including the Reasoning and Intelligence Online Test, are explicitly based on CHC theory.
The practical consequence for test design was significant. Tests built on CHC theory report not only a global IQ score but also index scores corresponding to the broad ability factors in the hierarchy. This means an examinee receives information about their verbal reasoning, spatial ability, working memory, and processing speed — not just a single number. The richness of that profile is directly traceable to Carroll's work and the theoretical integration that followed it.
Item response theory: a revolution in scoring
One of the most important but least visible developments in the history of IQ testing was the adoption of item response theory (IRT) in test scoring. Classical test theory — the scoring approach used in early intelligence tests — was based on raw scores: how many items did the examinee answer correctly? IRT, developed in the 1950s and 1960s by psychometricians including Frederic Lord and Georg Rasch, offered something more sophisticated: a mathematical model of the relationship between an individual's ability level and the probability of answering each specific item correctly.
Under IRT, each test item is characterized by parameters describing its difficulty, how well it discriminates between examinees of different ability levels, and (in some models) the probability of a correct response by guessing alone. The examinee's ability is then estimated from their pattern of correct and incorrect responses across all items, taking item characteristics into account. This produces a more accurate and stable estimate of ability than raw scores alone can provide, and it makes scores from different test forms directly comparable — a significant advantage for tests administered across different versions or at different time points.
IRT is also the foundation for computerized adaptive testing (CAT), in which a computer selects test items in real time based on the examinee's running ability estimate. When a person answers an item correctly, the next item is more difficult; when they answer incorrectly, the next item is easier. The result is a test that efficiently homes in on an examinee's ability level with fewer items than a fixed-format test would require. Many modern cognitive assessments — including online and computer-administered tests — use adaptive testing approaches made possible by IRT.
The digital era and the arrival of professional online testing
Computer-administered IQ tests began appearing in the early 1980s, as personal computers became more accessible. These early computerized tests were largely adaptations of existing paper instruments. Over the following two decades, computers became standard in educational and clinical settings, and by the early 2000s, many IQ tests could be administered via computer, with scoring handled automatically.
The COVID-19 pandemic accelerated a trend that was already underway. As in-person testing became impractical, many traditional tests adapted to teletherapy and video-based administration. This normalized the idea of assessment conducted outside the psychologist's office and demonstrated that cognitive testing could produce reliable, valid data in formats beyond the traditional face-to-face encounter.
Online testing — meaning tests that examinees take independently via the internet without a supervising clinician — represents a further step. The challenge for online testing has always been maintaining the quality standards that distinguish professional instruments from amateur quizzes. Most tests that have historically been available online were not created by professionals, were not normed on representative samples, and did not meet the technical and ethical standards that govern serious assessment. The result has been a landscape in which the word "IQ test" online typically meant something very different from what psychologists meant by the same phrase.
The diagram below summarizes how the major phases in IQ test development map to the evolving methods of administration:
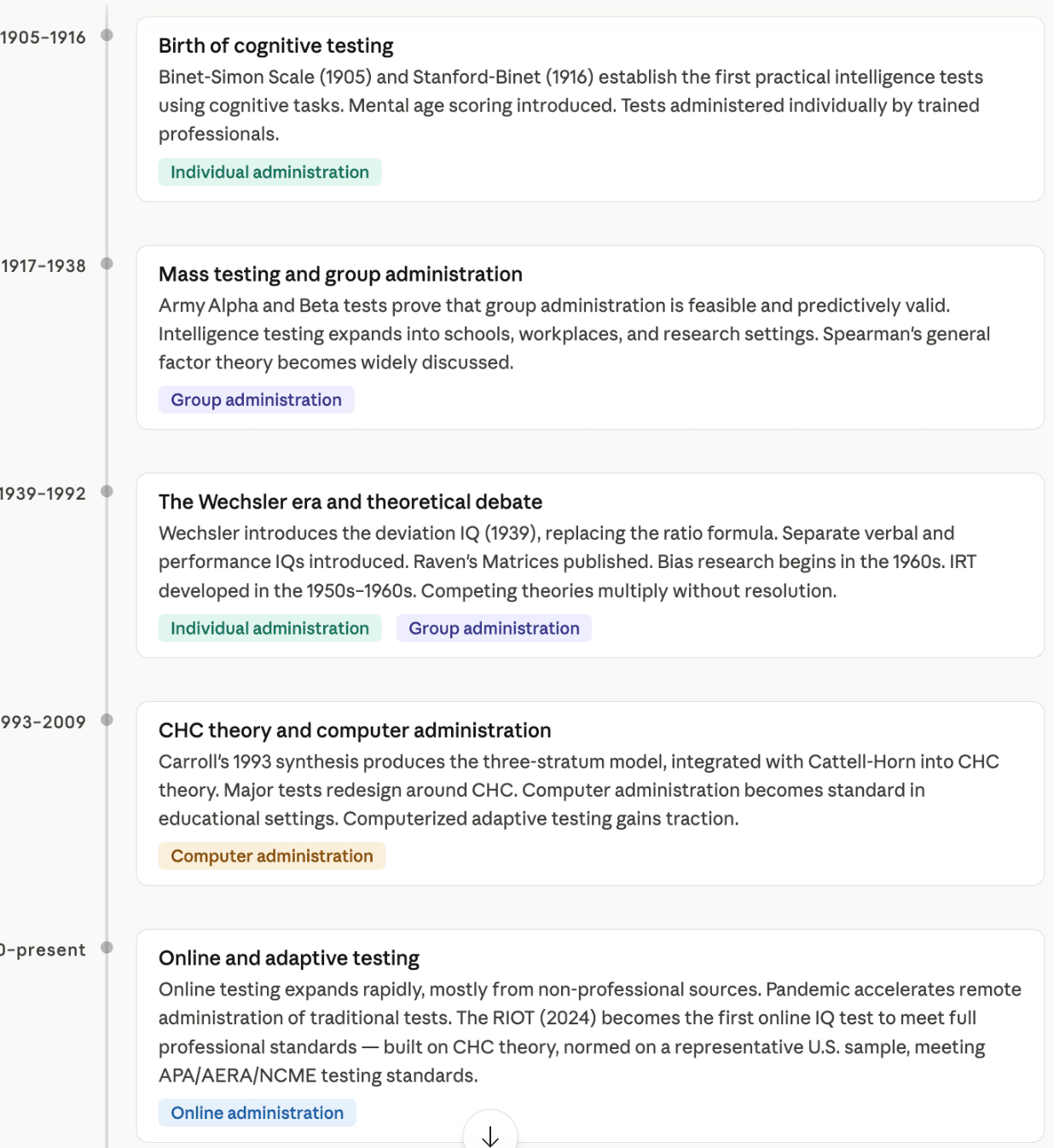
The diagram below summarizes how the major phases in IQ test development map to the evolving methods of administration:
What the history gets right about modern testing
Looking back across more than a century of development, a few themes emerge clearly. First, the field learned from its mistakes. The sensory approach failed and was abandoned. The ratio IQ formula had fundamental problems and was replaced. The eugenics-linked misuse of test data was exposed and scrutinized, and the methodological standards for detecting and avoiding bias were developed as a direct response. None of this happened quickly, and not all of the damage done along the way was undone. But the trajectory of the field has been toward greater rigor, not away from it.
Second, theory drove improvement. The shift from atheoretical item collections to CHC-based batteries produced tests that measure a richer and more valid cognitive profile. The graphic below shows what this shift looked like in terms of what tests report — from a single score to a structured hierarchy of abilities:
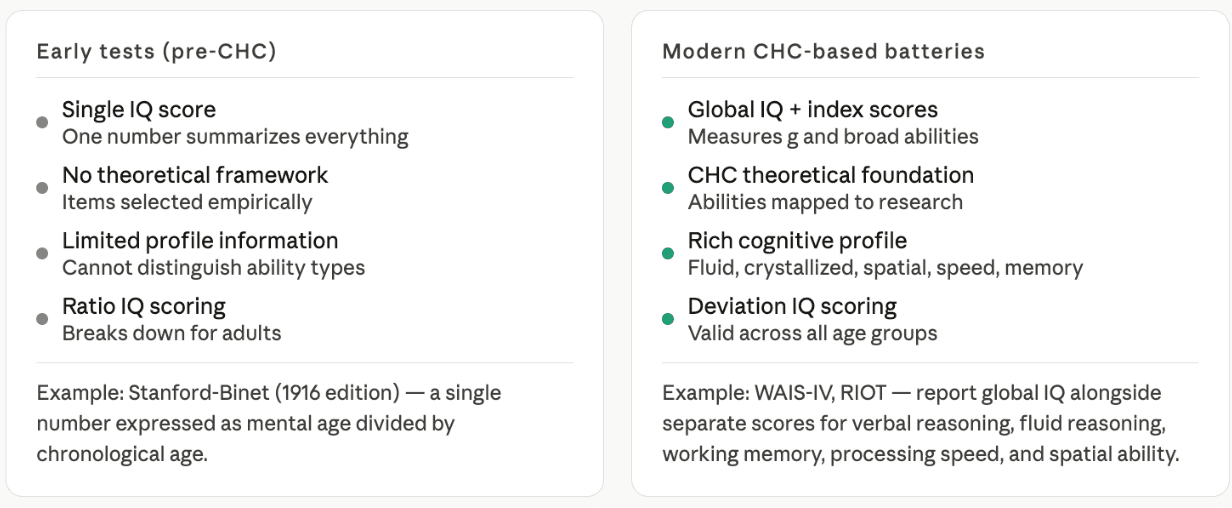
Third, the history shows that the core finding — that a general factor of cognitive ability exists and can be measured — has proven remarkably stable. The specific methods, scoring systems, and theoretical frameworks have all evolved, sometimes dramatically. But the basic empirical finding that Spearman identified in 1904 — that performance across diverse cognitive tasks is positively correlated, and that a common factor underlies that pattern — has been replicated in study after study across every culture and context where it has been tested. That robustness is part of what makes modern tests worth trusting: they are built on decades of cumulative research devoted to understanding exactly what they measure.
The Reasoning and Intelligence Online Test (RIOT)
The Reasoning and Intelligence Online Test (RIOT) is the most recent milestone in this history — the first online IQ test designed to meet the full professional standards that have governed serious cognitive assessment since the mid-20th century. It was built on the CHC model, the same theoretical foundation as the major clinical batteries produced over the past three decades. It underwent expert content review by specialists in cognitive, educational, and developmental psychology. Its items were piloted, statistically analyzed, and screened for bias before finalization. It was normed on the first properly representative U.S. sample ever assembled for a professional online IQ test. And it meets the Standards for Educational and Psychological Testing published by the American Educational Research Association, the American Psychological Association, and the National Council on Measurement in Education.
I developed the RIOT after 15 years of studying intelligence, and its design reflects everything the field has learned across more than a century of test development. The access barriers that have historically limited professional assessment — cost, geographic location, the requirement for an appointment with a licensed psychologist — are real, and the RIOT addresses them without sacrificing the rigor that makes the scores trustworthy.
Parting thoughts
The history of IQ testing is not a story of unambiguous progress. Some chapters of that history are genuinely embarrassing, and the damage done by the misapplication of intelligence test data in the early 20th century was real. But the scientific core of the enterprise — the attempt to measure cognitive ability in ways that are reliable, valid, and useful — has proven durable, and the methods for doing so have improved enormously.
Modern IQ tests are not the same instruments that Terman used to advocate for eugenics or that Yerkes used to argue for immigration restriction. They are the product of sustained correction, refinement, and increasingly rigorous standards. Understanding that history is not only intellectually satisfying — it is necessary for anyone who wants to use or interpret cognitive assessment data with appropriate care and honesty.
Sources
- Carroll, J. B. (1993). Human cognitive abilities: A survey of factor-analytic studies. Cambridge University Press.
- Warne, R. T. (2020). In the know: Debunking 35 myths about human intelligence. Cambridge University Press.
- Spearman, C. (1904). "General intelligence," objectively determined and measured. American Journal of Psychology, 15(2), 201–293.
- Binet, A., & Simon, T. (1905). Méthodes nouvelles pour le diagnostic du niveau intellectuel des anormaux. L'Année Psychologique, 11, 191–244. https://doi.org/10.3406/psy.1904.3675
- Terman, L. M. (1916). The measurement of intelligence. Houghton Mifflin.
- Wechsler, D. (1939). The measurement of adult intelligence. Williams & Wilkins.
- McGrew, K. S. (2009). CHC theory and the human cognitive abilities project. Intelligence, 37(1), 1–10.
- Schneider, W. J., & McGrew, K. S. (2018). The Cattell-Horn-Carroll theory of cognitive abilities. In D. P. Flanagan & E. M. McDonough (Eds.), Contemporary intellectual assessment (4th ed.). Guilford Press.
- Flanagan, D. P., & Harrison, P. L. (Eds.). (2012). Contemporary intellectual assessment: Theories, tests, and issues (3rd ed.). Guilford Press.
- Neisser, U., et al. (1996). Intelligence: Knowns and unknowns. American Psychologist, 51(2), 77–101.
- American Educational Research Association, American Psychological Association, & National Council on Measurement in Education. (2014). Standards for educational and psychological testing. AERA.
- Flanagan, D. P., Ortiz, S. O., & Alfonso, V. C. (2013). Essentials of cross-battery assessment (3rd ed.). Wiley.
- Hambleton, R. K., Swaminathan, H., & Rogers, H. J. (1991). Fundamentals of item response theory. Sage.
Take our professional IQ test
Want to know your IQ? Try the first ever professional online IQ test.
Article Categories
All ArticlesUnderstanding IQ ScoresTaking an IQ TestRIOT-Specific InformationGeneral IQ & IntelligenceAdvanced Topics & ResearchIQ Scores & InterpretationMensa & High-IQ SocietiesOnline IQ Tests IQ Test Basics & FundamentalsAverage IQ & DemographicsFamous People & IQHistory & Origins Of IQ TestingAccuracy, Reliability & CriticismSpecial Population & Related ConditionsImproving IQ / PreparationSpecific IQ Tests & FormatsIQ Testing for HR & RecruitmentSkills Assessment
Related Articles
The Evolution of IQ Testing: A Historical PerspectiveIQ Tests: Understanding the ControversiesThe Role of IQ Tests in Education and Career AssessmentTop 10 Facts About IQ Tests Everyone Should KnowThe Past and Future of IQ Tests: 120 Years of Measuring Human IntelligenceHow Old Are IQ Tests?How is IQ Measured or Calculated?Why Were IQ Tests CreatedDo Schools Test For IQ?How Are IQ Tests CreatedWhen Was IQ Testing Invented?How Do IQ Tests Work?Who Invented the IQ Test?
Take our IQ testsCompare all tests
Basic IQ Test
5 subtests + 5 cognitive abilities
Features
- ~13 Minutes
- IQ score
- Cognitive abilities breakdown
- ±5.6 IQ margin of error
5/15 Subtests
Learn moreVocabulary
Matrix Reasoning
SToVeS
Visual Reversal
Symbol Search
Full IQ Test
15 subtests + all cognitive abilities
Features
- ~52 Minutes
- IQ score
- Cognitive abilities breakdown
- ±3.7 IQ margin of error
15/15 Subtests
Learn moreVocabulary, Information, Analogies
Matrix Reasoning, Visual Puzzles, Figure Weights
Object Rotation, SToVeS, Spatial Orientation
Computation Span, Exposure Memory, Visual Reversal
Symbol Search, Abstract Matching
Simple Reaction Time, Choice Reaction Time
Community
Intelligence Journals & Organizations
Our Articles