Jun 17, 2026·Specific IQ Tests & Formats
A Guide to the Different Types of IQ Tests Available
Wondering which IQ test to take? Discover the difference between clinical WAIS exams, group tests, and online options. Read the guide and try the RIOT test!
One question I hear frequently from people who are curious about their own intelligence is a version of: "Which IQ test should I take?" It sounds like a simple question, but answering it well requires understanding something that most people don't realize at the outset — that "IQ test" is not a single thing. It describes a broad category of instruments that differ substantially in format, content, administration method, intended population, and psychometric quality. Choosing a test without understanding those differences is a bit like going to a pharmacy and asking for "some medicine" without knowing what condition needs treating.
This article is a practical guide to navigating those differences. The goal is not to survey every test in existence — there are hundreds — but to explain the major categories clearly enough that anyone considering an IQ assessment can make an informed decision.
Why different tests produce different scores
Before sorting tests by type, it is worth addressing something that confuses many people: different professionally developed IQ tests, administered to the same person, will often produce slightly different scores. This does not mean any of the tests is wrong. It reflects a fundamental principle in intelligence research that Charles Spearman called the "indifference of the indicator."
Spearman demonstrated in his foundational 1904 paper that performance on cognitive tasks correlates positively across virtually all tasks that require thinking, reasoning, or problem solving — regardless of what the tasks look like on the surface. Someone who scores well on a vocabulary test tends to score well on a spatial reasoning test and on a matrix reasoning test, even though those tasks appear unrelated. This positive correlation across tests reflects the influence of a common underlying factor, which Spearman called general intelligence, or g.
The implication is that the specific content of an IQ test is less important than whether the tasks require genuine cognitive effort. A vocabulary test, a matrix puzzle, a digit span task, and a mental rotation problem are all indicators of the same underlying ability. What matters is whether the test is constructed according to professional standards — not whether it uses the specific tasks favored by any particular tradition.
Classification by administration method
The most common way to classify IQ tests is by how they are administered. This has important practical consequences for what the test can measure and for whom it is appropriate.
Individually administered tests
Individually administered tests are given to one examinee at a time, typically by a trained psychologist or clinician. The examiner works directly with the test taker, presenting materials, recording responses, and timing items. Many of the tasks on these tests cannot be group-administered — they involve physical manipulation of objects, verbal interaction, or observational scoring that requires an examiner to be present.
The gold standard tests in clinical and educational psychology — the Wechsler Adult Intelligence Scale (WAIS), the Wechsler Intelligence Scale for Children (WISC), and the Stanford-Binet Intelligence Scales — are all individually administered. Research on the long-term stability of WISC scores has found that the Full Scale IQ and certain index scores are sufficiently stable across multi-year intervals to support normative comparisons, though individual subtest scores show more variability over time — a finding that underscores the value of relying on composite scores rather than narrow subtest patterns.
 The strengths of individual administration are substantial. The examiner can observe how the examinee approaches problems — whether they work methodically or impulsively, whether they appear to be putting forth full effort, whether anxiety appears to be interfering with performance. That behavioral observation adds clinical value that a score alone cannot provide. The examiner can also adapt the pace, offer standardized encouragement, and ensure that the examinee understands the instructions for each task.
The strengths of individual administration are substantial. The examiner can observe how the examinee approaches problems — whether they work methodically or impulsively, whether they appear to be putting forth full effort, whether anxiety appears to be interfering with performance. That behavioral observation adds clinical value that a score alone cannot provide. The examiner can also adapt the pace, offer standardized encouragement, and ensure that the examinee understands the instructions for each task.
The strengths of individual administration are substantial. The examiner can observe how the examinee approaches problems — whether they work methodically or impulsively, whether they appear to be putting forth full effort, whether anxiety appears to be interfering with performance. That behavioral observation adds clinical value that a score alone cannot provide. The examiner can also adapt the pace, offer standardized encouragement, and ensure that the examinee understands the instructions for each task.The tradeoff is cost and accessibility. A full clinical assessment using a Wechsler battery or Stanford-Binet typically takes two to four hours to administer, requires a licensed psychologist, and can cost several hundred to several thousand dollars. That expense is fully justified when the results will inform a clinical or educational decision. For someone who simply wants to understand their cognitive profile, it has historically been prohibitive.
Group-administered tests
Group-administered tests are designed for simultaneous use with multiple examinees. Because they must function without an individual examiner monitoring each test taker, they are typically paper-and-pencil or computer-based, consist entirely of multiple-choice items, and are self-paced within time limits.
Group testing became practical at scale during World War I, when the Army Alpha and Army Beta tests were administered to over two million military recruits. That accomplishment demonstrated that intelligence testing was feasible outside the clinical setting and that group-administered scores had genuine predictive validity for training outcomes and job performance.
Today, group-administered cognitive tests are widely used in education — the Cognitive Abilities Test (CogAT) is one common example, used to identify students for gifted programs and to guide instructional planning. The military continues to use the Armed Services Vocational Aptitude Battery (ASVAB), which is administered to more than one million applicants annually and functions as a practical measure of cognitive ability for military selection and placement. The composite Armed Forces Qualification Test (AFQT) score derived from four of the ASVAB's subtests correlates with other measures of general cognitive ability and predicts training outcomes and job performance in ways consistent with general intelligence research.
The same principle extends to educational tests: the SAT and ACT correlate strongly enough with validated intelligence tests that their scores can be converted to approximate IQ equivalents.
Group tests sacrifice the observational depth of individual administration. There is no examiner to note behavioral cues, offer encouragement, or verify that instructions are understood. For screening purposes — where the goal is to identify a subset of a large population for further evaluation — that tradeoff is generally acceptable. For diagnostic purposes involving important decisions about an individual, a group test alone is typically not sufficient.
Online tests
Online IQ testing is the newest category and the most uneven in quality. The internet has made it trivially easy to put a test online and call it an IQ test, with no requirement for professional training, technical documentation, or a legitimate norm sample. The result is a landscape where hundreds of amateur tests coexist alongside the handful of professionally developed ones.
The online format itself introduces no inherent psychometric disadvantage. Research evaluating online administration of established cognitive measures has found acceptable reliability and validity compared to paper-based administration when the underlying test is properly designed. What separates professional online tests from amateur ones is not the delivery channel — it is whether the test behind the interface was built to professional standards, with representative norming, documented technical properties, and identified expert authors.
Classification by content structure
Beyond how a test is administered, tests also differ significantly in how their content is structured. This classification crosses the administration categories: both individually and group-administered tests can be either batteries or single-format tests.
IQ test batteries
A test battery consists of multiple subtests, each measuring a different type of cognitive task. The battery's global IQ score reflects performance aggregated across all those subtests. This structure has a major psychometric advantage: by sampling broadly across the cognitive domains identified by CHC theory — verbal reasoning, fluid reasoning, spatial ability, working memory, processing speed — a battery reduces the influence of any individual task's idiosyncrasies on the final score.
Every major individually administered test is a battery. The WAIS-IV, for example, includes ten core subtests spanning four index domains. The Woodcock-Johnson Tests of Cognitive Abilities (WJ V) is notable for its particularly comprehensive CHC coverage and its integrated co-normed design, which allows direct comparison of cognitive ability scores with academic achievement scores from the same normative sample — a feature that makes it especially powerful for diagnosing specific learning disabilities.
The Reasoning and Intelligence Online Test (RIOT) is also a battery. Its 15 subtests span six cognitive indices — Verbal Reasoning, Fluid Reasoning, Spatial Ability, Working Memory, Processing Speed, and Reaction Time — along with a global IQ score. The multi-domain structure reflects the CHC hierarchy directly, and the resulting score report provides a profile of cognitive strengths and weaknesses rather than just a single number. That granularity matters for any application where understanding the pattern of abilities — not just their overall level — is useful.
Single-format tests
Single-format tests present one type of task throughout. The most widely known example is the Raven's family of tests. All Raven's variants present the same item format: a 3×3 matrix with one cell missing, and the examinee must identify which of several options correctly completes the pattern.
The Raven's tests were originally developed in part because their nonverbal format was thought to make them less sensitive to cultural and linguistic background than traditional verbal intelligence tests — a design goal that earned them the label "culture-fair tests." That premise has proven more complicated than originally believed, as research has shown that performance on nonverbal matrix tasks still depends on familiarity with abstract geometric concepts and the conventions of multiple-choice testing. Still, the Raven's family includes well-validated instruments — particularly the Standard Progressive Matrices (SPM) and the Advanced Progressive Matrices (APM) — that are widely used in research and occupational settings.
Single-format tests have a practical advantage in brevity and simplicity. They are generally faster to administer than full batteries and easier to standardize across different contexts. Their limitation is coverage: by measuring only one type of cognitive task, they cannot produce the domain-specific profile that batteries provide. A score on the Raven's is a strong measure of fluid reasoning and g, but it says nothing specific about verbal ability, working memory, or processing speed.
Classification by population
Another important dimension is which population a test is designed for. This matters because IQ scores are interpretable only relative to a norm sample, and a norm sample that does not represent the intended population produces distorted scores.
Adult tests
Tests designed for adults typically set their lower age boundary around 16 to 18. The WAIS-IV covers ages 16 through 90, making it appropriate across a wide range of adult life stages. The RIOT is designed for adults 18 and older, reflecting the normative data and item calibration that went into its development.
An important characteristic of adult IQ tests is that they account for the different cognitive trajectories of fluid and crystallized abilities across the lifespan. Tasks measuring processing speed and fluid reasoning tend to show decline in older adults, while tasks measuring accumulated verbal knowledge remain stable or even improve into late adulthood. A well-designed adult battery compares an examinee's performance to others in the same age group — which is what a deviation IQ does — so that an examinee in their 60s is not disadvantaged relative to 25-year-olds on tasks where processing speed naturally declines with age.
Tests for children
The first IQ tests were designed specifically for children. Alfred Binet's original 1905 scale was developed to identify French schoolchildren who needed additional educational support, and the concept of mental age — comparing a child's cognitive performance to the average performance of children at various chronological ages — was central to his approach.
Today, the major individually administered tests for children include the WISC-V (ages 6 through 16), the Stanford-Binet 5th Edition (ages 2 through 85+), the Woodcock-Johnson V (ages 2 through 90+), and the Differential Ability Scales. For group administration in educational settings, the CogAT is widely used from kindergarten through 12th grade. At present, there are no professionally developed online IQ tests for children — the legitimate online options, including the RIOT, are designed for adult populations only.
Tests for special populations
Some tests are designed specifically for examinees who may not perform well on standard tests for reasons unrelated to intelligence — including individuals with language difficulties, hearing impairments, or limited familiarity with English. The Raven's family occupies this niche in part because its matrix format requires no verbal instructions or verbal responses. The Leiter International Performance Scale is another example, designed to assess nonverbal intelligence through tasks that require no language from either the examiner or the examinee.
These tests serve a legitimate purpose. When a standard battery would disadvantage an examinee because of a specific characteristic unrelated to intelligence, a nonverbal test may provide a more accurate estimate of cognitive ability. The key caveat — consistent with the broader research on culture-fair testing — is that no test is entirely free of cultural demands. Performance on any intelligence test requires familiarity with the testing context and the cognitive frameworks the test draws on. Psychologists using these tests with examinees outside the intended population are responsible for evaluating whether the test is functioning appropriately for that individual.
Classification by theoretical framework
Behind every professionally developed IQ test is an explicit theoretical model of what intelligence is and how its components relate to one another. The theory shapes the test's structure, the interpretation of its scores, and the research that can be done with it.
The CHC framework is now the dominant theoretical basis in professional testing. Its advantage is that it is grounded in decades of factor-analytic research rather than any single theorist's intuitions. When tests built on CHC theory produce broadly similar score profiles for the same examinee, that convergence is expected: the tests are measuring the same underlying structure, just using different tasks to access it.
Tests built on alternative theories — such as the PASS model — can still produce valid and useful information, but their scores will not map directly onto CHC domain scores, which can complicate interpretation when multiple tests are used with the same examinee.
What professional quality requires, regardless of type
Across all these categories — individual, group, and online; battery and single-format; adult and child populations — the requirements for a professionally developed test are the same. A credible test must have an identified expert creator with disclosed credentials, documented technical properties (typically in the form of a test manual), independent expert review of its content, and a norm sample that was deliberately recruited to be representative of the test's intended population.
These requirements exist because IQ scores are consequential data. They inform decisions in education, clinical assessment, and employment. A test that does not meet these standards cannot provide accurate scores, regardless of how polished its interface looks or how compelling its marketing claims are.
The norm sample requirement deserves particular emphasis because it is the requirement that most online tests fail. An IQ score is not an absolute number — it expresses performance relative to a reference group. If that reference group is not representative of the intended testing population, the comparisons it produces are meaningless. A test whose norm group consists of self-selected test takers from the internet is producing scores that compare examinees to a systematically unusual subset of the population, not to a representative one. This is a purely technical matter with no workarounds.
How to choose between types
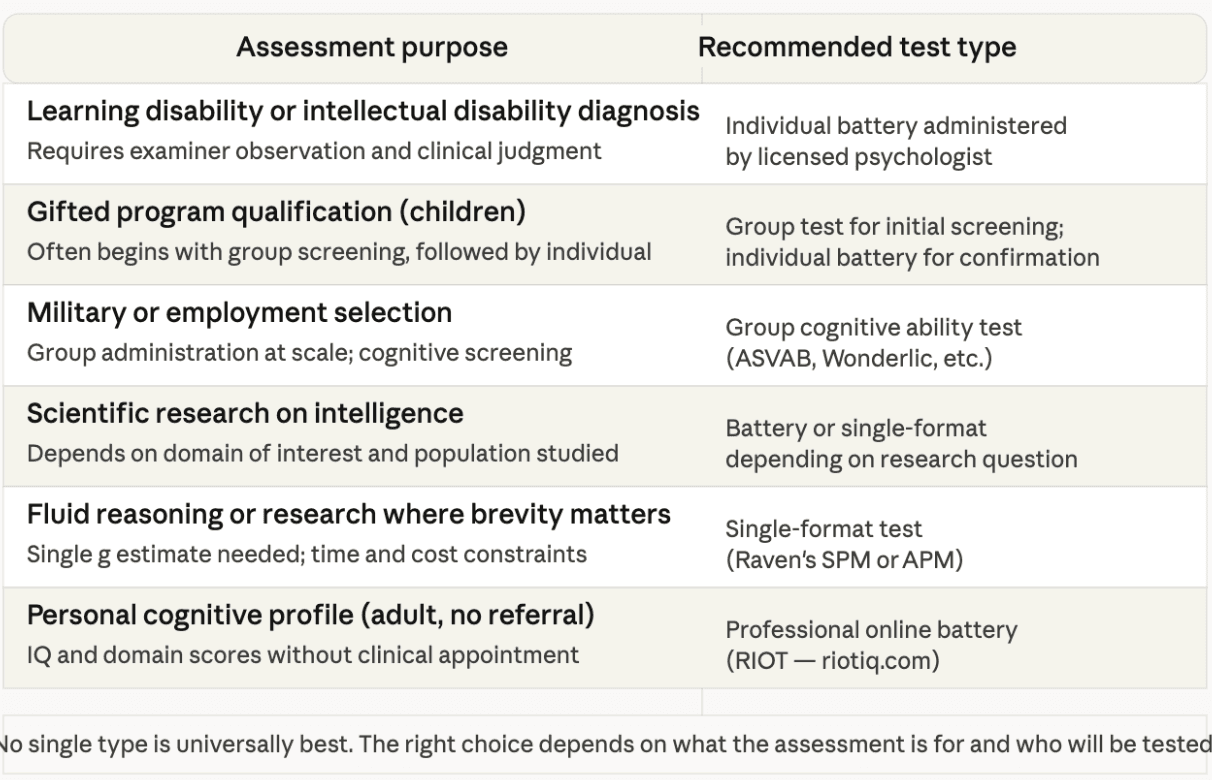
The choice of test type should follow from the purpose of the assessment. A few principles are useful in making that decision.
For clinical or diagnostic purposes — identifying a learning disability, assessing cognitive functioning as part of a psychological evaluation, or determining eligibility for special education services — an individually administered battery by a qualified clinician is appropriate. The behavioral data that an examiner collects, and the comprehensive profile a full battery produces, are essential for clinical interpretation.
For large-scale educational screening — deciding which students to refer for gifted program evaluation, or identifying students who may benefit from additional support — a group-administered test is efficient and appropriate, with the expectation that students who score at the extremes will typically be evaluated individually as a follow-up.
For research purposes, the specific test choice often depends on the population being studied, the cognitive domains of interest, and practical constraints of time and cost. The Raven's Progressive Matrices remain widely used in research for their brevity and sensitivity to fluid reasoning, even though they produce only a single score. Researchers needing domain-specific ability profiles typically opt for full batteries.
For individuals who want to understand their own cognitive profile without a clinical referral, a professionally developed online test offers a genuine option that did not exist until recently. The key distinction is between tests built to professional standards and the many amateur tests that look similar but lack them.
The following panel summarizes the appropriate use cases for the major test types:
The specific tests most commonly encountered
A brief orientation to the tests that most people are likely to encounter in practice is useful here.
The Wechsler scales are the most widely used individual intelligence tests in the world. The WAIS-IV for adults and the WISC-V for children are the versions currently in widespread clinical use. Both produce a Full Scale IQ along with index scores across four domains. The Wechsler tests have an extensive research base accumulated across multiple editions over nearly a century of use. Cross-test research comparing the WISC-V and the Stanford-Binet has found that Full Scale IQ scores from the two tests correlate at approximately .78 to .88, confirming that well-designed batteries measuring the same construct tend to produce consistent results even when they use different tasks.
The Stanford-Binet Intelligence Scales, Fifth Edition, covers a notably broad age range — from age two through late adulthood — and is firmly grounded in CHC theory. It is particularly valued in clinical settings where comparison across a wide age span is needed, such as longitudinal assessments of cognitive development.
The Woodcock-Johnson V is distinguished by its comprehensive CHC coverage and its integrated co-normed design: its cognitive ability, academic achievement, and oral language batteries share the same normative sample, allowing direct comparison of ability and achievement. This makes it especially powerful for diagnosing specific learning disabilities or evaluating ability-achievement gaps.
The Raven's Progressive Matrices — including the Standard Progressive Matrices (SPM) for the general adult population and the Advanced Progressive Matrices (APM) for populations likely to score in the upper ranges — are the most widely used single-format tests in research and occupational assessment. Their matrix format is genuinely compact and efficient for measuring fluid reasoning and g, though they provide no domain-level scores and their culture-fairness claims should not be taken at face value.
Taking a professional IQ test online
For adults who want to obtain a validated cognitive assessment without going through the clinical route, the Reasoning and Intelligence Online Test (RIOT) is the first and currently only online IQ test built to meet the same professional standards as traditional face-to-face batteries. The RIOT reports a global IQ score along with six cognitive index scores and 16 individual subtest T-scores — a depth of reporting comparable to what a clinical battery provides, delivered through a self-administered online format completable in approximately 60 minutes. A free sample version is available at riotiq.com for those who want to experience the format before taking the full assessment.
References
- Spearman, C. (1904). "General intelligence," objectively determined and measured. American Journal of Psychology, 15(2), 201–293. https://doi.org/10.2307/1412107
- Carroll, J. B. (1993). Human cognitive abilities: A survey of factor-analytic studies. Cambridge University Press. https://doi.org/10.1017/CBO9780511571312
- Warne, R. T. (2020). In the know: Debunking 35 myths about human intelligence. Cambridge University Press. https://doi.org/10.1017/9781108593298
- Warne, R. T. (2025). Technical manual for the Reasoning and Intelligence Online Test, version 1.0. RIOT IQ. https://riotiq.com
- American Educational Research Association, American Psychological Association, & National Council on Measurement in Education. (2014). Standards for educational and psychological testing. https://www.testingstandards.net
- Flanagan, D. P., & Dixon, S. G. (2014). The Cattell-Horn-Carroll theory of cognitive abilities. Encyclopedia of Special Education. Wiley. https://onlinelibrary.wiley.com/doi/full/10.1002/9781118660584.ese0431
- Reynolds, M. R., & Keith, T. Z. (2020). Beyond individual intelligence tests: Application of Cattell-Horn-Carroll theory. Intelligence, 79, 101433. https://doi.org/10.1016/j.intell.2020.101427
- McGill, R. J., & Canivez, G. L. (2022). Long-term stability of WISC-V scores in a clinical sample. Applied Neuropsychology: Child. https://pmc.ncbi.nlm.nih.gov/articles/PMC8967112/
- Roid, G. H., & Pomplun, M. (2012). The Stanford-Binet Intelligence Scales, Fifth Edition. In Contemporary intellectual assessment: Theories, tests, and issues (3rd ed.). Guilford Press.
- Roberts, R. D., Goff, G. N., Anjoul, F., Kyllonen, P. C., Pallier, G., & Stankov, L. (2000). The Armed Services Vocational Aptitude Battery (ASVAB): Little more than acculturated learning? Learning and Individual Differences, 12(1), 81–103. https://doi.org/10.1016/S1041-6080(00)00035-2
- Martin, J., Mashburn, C. A., & Engle, R. W. (2020). Improving the validity of the Armed Services Vocational Aptitude Battery with measures of attention control. Journal of Applied Research in Memory and Cognition. https://pmc.ncbi.nlm.nih.gov/articles/PMC10744611/
- Balboni, G., Belacchi, C., Bonichini, S., & Cubelli, R. (2010). Short form of the Raven's Coloured Progressive Matrices. British Journal of Developmental Psychology. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12351228/
- Mayes, S. D., & Calhoun, S. L. (2004). Similarities and differences in WISC-III and WAIS-IV scores in adults with intellectual disability. Research in Developmental Disabilities. https://pmc.ncbi.nlm.nih.gov/articles/PMC2854585/
- Wiebe, S. A., & Bauer, P. J. (2012). Evaluating an online version of the CFT 20-R. Frontiers in Psychology. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9029809/
- Gottfredson, L. S. (1997). Why g matters: The complexity of everyday life. Intelligence, 24(1), 79–132. https://doi.org/10.1016/S0160-2896(97)90014-3
Take our professional IQ test
Want to know your IQ? Try the first ever professional online IQ test.
Article Categories
All ArticlesUnderstanding IQ ScoresTaking an IQ TestRIOT-Specific InformationGeneral IQ & IntelligenceAdvanced Topics & ResearchIQ Scores & InterpretationMensa & High-IQ SocietiesOnline IQ Tests IQ Test Basics & FundamentalsAverage IQ & DemographicsFamous People & IQHistory & Origins Of IQ TestingAccuracy, Reliability & CriticismSpecial Population & Related ConditionsImproving IQ / PreparationSpecific IQ Tests & FormatsIQ Testing for HR & RecruitmentSkills Assessment
Related Articles
How to Solve 3x3 Visual Matrix Reasoning Puzzles Step by StepWhat Are IQ Tests and How Do They Work?A Guide to the Different Types of IQ Tests AvailableWhat Are Professional IQ Tests and How Do They Work?5 Types of IQ Tests ExplainedWhat Is a Matrix Reasoning Test? What the Pattern Puzzles MeasureTop 10 Online IQ Tests: A Comprehensive ComparisonRIOT IQ vs. Wonderlic Test Prep: Professional Assessment or Test Coaching?RIOT IQ vs. Wonderlic Test Practice: Which Cognitive Assessment Serves Your Needs?RIOT IQ vs. Assessment Day: Which CCAT Approach Delivers Real Value?RIOT IQ vs. Prepopedia: Which CCAT Solution Fits Your Needs?RIOT IQ vs. Job Test Prep: Which CCAT Preparation Approach Makes Sense?RIOT IQ vs. 12 Min Prep: Which CCAT Preparation Option Works Best?How Is the Stanford-Binet Intelligence Scale Used?How Does the Stanford-Binet IQ Test Work?What Is the WAIS IQ Test?Which IQ Test Should I Take?Military IQ and the ASVABIQ Tests for KidsThe Stanford–Binet Intelligence TestIs the SAT an IQ Test?What Are Reliable IQ Tests?The Wechsler IQ Tests
Take our IQ testsCompare all tests
Basic IQ Test
5 subtests + 5 cognitive abilities
Features
- ~13 Minutes
- IQ score
- Cognitive abilities breakdown
- ±5.6 IQ margin of error
5/15 Subtests
Learn moreVocabulary
Matrix Reasoning
SToVeS
Visual Reversal
Symbol Search
Full IQ Test
15 subtests + all cognitive abilities
Features
- ~52 Minutes
- IQ score
- Cognitive abilities breakdown
- ±3.7 IQ margin of error
15/15 Subtests
Learn moreVocabulary, Information, Analogies
Matrix Reasoning, Visual Puzzles, Figure Weights
Object Rotation, SToVeS, Spatial Orientation
Computation Span, Exposure Memory, Visual Reversal
Symbol Search, Abstract Matching
Simple Reaction Time, Choice Reaction Time
Community
Intelligence Journals & Organizations
Our Articles