What Are Professional IQ Tests and How Do They Work?
What makes an IQ test legitimate? Discover how professional IQ tests work, how they are scored, and what makes them valid. Read the guide and take the RIOT!
Most people have encountered the term "IQ test" at some point in their lives, but relatively few have taken a professionally developed one. The distinction matters more than most people realize. The phrase "IQ test" is applied casually to everything from a 10-question quiz on a free website to a multi-hour battery administered by a licensed psychologist. These are not the same thing, and treating them as equivalent leads to misunderstanding both the value and the limitations of intelligence testing.
I have spent more than 15 years studying human intelligence and developing professional cognitive assessments. What follows is a clear explanation of what professional IQ tests actually are, what makes them different from amateur alternatives, and how the process of building a legitimate test works.
What makes an IQ test "professional"?
A professional IQ test is a scientific instrument. That framing is deliberate. Just as a medical diagnostic device must meet standards for accuracy, reproducibility, and appropriate use, a professional IQ test must meet published technical and ethical standards before it is used to produce scores that affect people's lives. The most widely used set of standards in the United States is theStandards for Educational and Psychological Testing, published jointly by the American Educational Research Association (AERA), the American Psychological Association (APA), and the National Council on Measurement in Education (NCME). These standards have been developed collaboratively since 1966 and represent the field's consensus on what responsible test development and use looks like.
Meeting those standards is not a single-step process. It involves every stage of a test's development — from the initial theoretical framework, to how items are written and evaluated, to how the scoring system is constructed, to how scores are reported and used. A test cannot be certified as meeting the
Take our professional IQ test
Want to know your IQ? Try the first ever professional online IQ test.
from the outside, but professional test creators are expected to document their efforts to adhere to them.
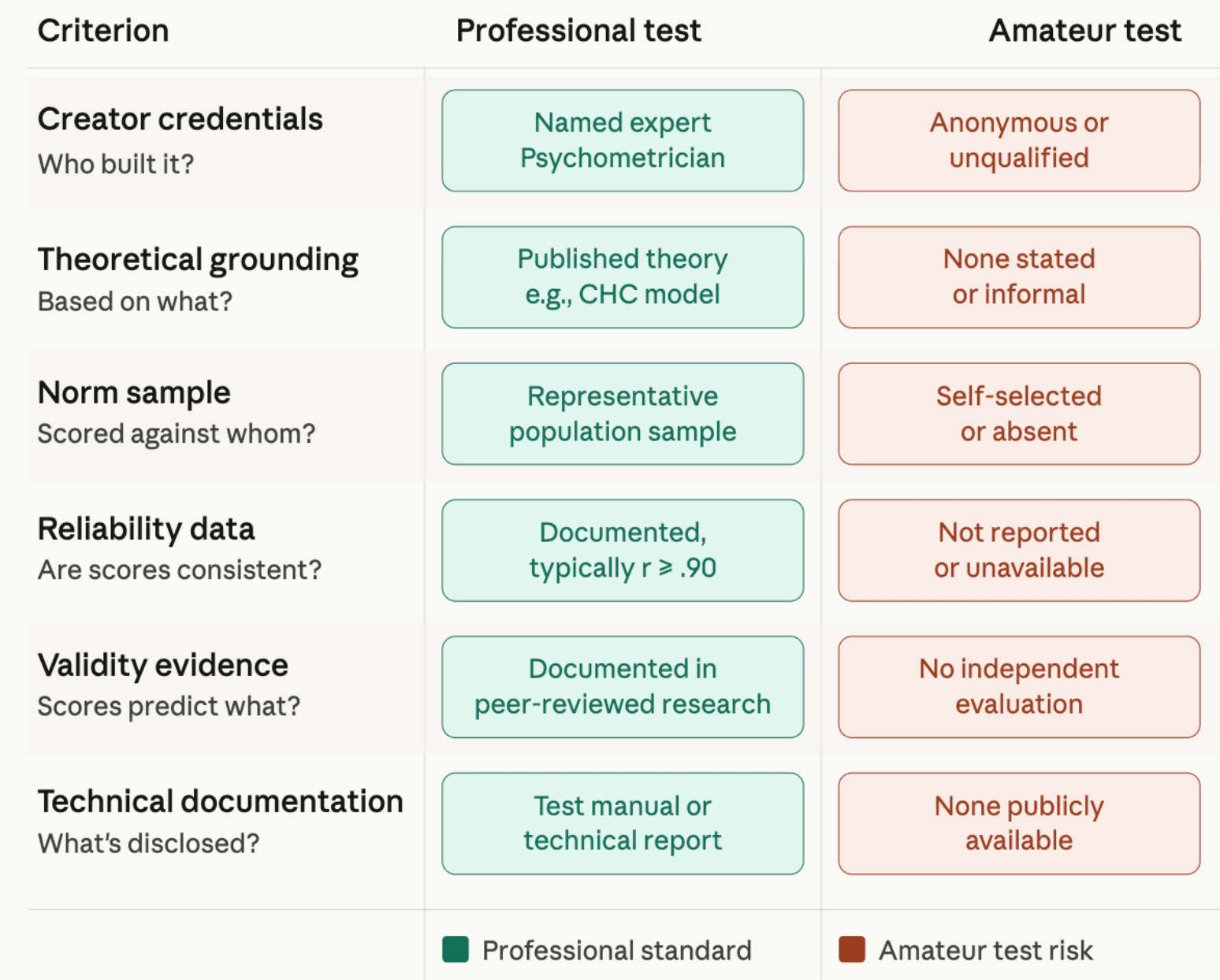
The single most important feature separating professional tests from amateur ones is the expertise and accountability of the people behind them. Professional test creators are trained in psychometrics, the science of psychological measurement, and are identifiable by name and credential. Anonymous test creators cannot be held responsible for errors, biases, or misleading score interpretations — which is reason enough to set any anonymous test aside.
What does theoretical grounding actually do?
Before a single question is written, professional test creators work out the theoretical framework that will guide every subsequent decision. A theory of intelligence is not decorative — it determines what abilities the test measures, how many subtests it includes, and what subscores it reports alongside an overall IQ.
The dominant theoretical framework in intelligence research today is the Cattell-Horn-Carroll (CHC) theory. This hierarchical model places general intelligence (g) at the top of a three-level structure. Below it sit broad abilities — fluid reasoning, crystallized intelligence, processing speed, working memory, and others. Below those are narrower, more specific abilities. The CHC modelemerged from decades of factor-analytic research, most prominently from John B. Carroll's 1993 reanalysis of over 400 datasets, and it represents the mainstream consensus in the field.
If a test is built on CHC theory, the developer knows they need to sample from multiple broad ability domains — not just verbal reasoning — to produce a score that captures general intelligence accurately. A test built on no theory produces an IQ score with no principled interpretation.
How are test items actually developed?
Item development is where the work of test creation becomes most labor-intensive, and where amateur attempts most visibly fall short. The process has several distinct stages.
First, test creators select tasks that will appear on the test. For a battery like theReasoning and Intelligence Online Test (RIOT), tasks must collectively sample a broad enough range of cognitive abilities to support an overall IQ score and meaningful subscores. Each task type has documented strengths and weaknesses, and a well-designed battery balances those across subtests.
Once task types are selected, individual items are written. Writing items that actually measure the intended cognitive process — rather than cultural knowledge, reading speed, or test-taking strategy — requires expertise that most people underestimate. Modern item development usesitem response theory (IRT), a statistical modeling framework that examines the relationship between a person's ability and their probability of answering a given item correctly. IRT analysis can identify items that are too easy, too hard, that provide little information at specific ability levels, or that do not function similarly across demographic groups.
After initial items are drafted, they go through a piloting phase: administered to a sample of test takers, analyzed statistically, and revised or discarded accordingly. Expert review is often part of this process. For the RIOT, the content was evaluated by a panel of experts drawn from cognitive, educational, and developmental psychology before the test was released.
What is reliability, and why does it matter?
Reliability refers to the consistency of test scores. A test is reliable if it produces similar scores for the same person under similar conditions. Because intelligence is believed to be a relatively stable trait throughout most of the adult lifespan, IQ scores should also be stable. If an examinee received a score of 115 today and a score of 85 a month later — with no intervening head trauma or neurological event — something is wrong with the test.
Reliability is expressed as a coefficient ranging from 0 to 1, with higher values indicating greater consistency. Well-designed professional tests routinely achieve Full Scale IQ reliability coefficients at or above .90. Research on the Wechsler Adult Intelligence Scale foundtest-retest correlations of .897 for Full Scale IQ across intervals of one to ten years. The WAIS-IV's internal consistency coefficients for subtests rangefrom .87 to .98 by Cronbach's alpha. These are the benchmarks professional tests are held to.
It is worth noting that reliability is a property of test scores, not of the test itself. Scores can be more or less reliable depending on the population of test takers, the testing conditions, and the ability level being assessed. Professional test creators document reliability for specific populations and specific conditions — a blanket claim that "the test is reliable" is scientifically imprecise.
What is validity, and how is it established?
Validity is the most important property a test can have — and the most frequently misunderstood. Validity is not a property of the test itself. It is a property of the uses and interpretations of test scores. A score can be valid for one purpose and not another.
Professional test creators establish validity evidence in several ways. The most relevant for IQ tests include content validity (do the items genuinely measure cognitive processes, as intended by the theory?), structural validity (does the internal structure of the scores match the theoretical structure of the construct?), and criterion-related validity (do scores predict outcomes they theoretically should predict?). This last type is particularly well-documented in intelligence research.Research consistently shows that IQ scores predict academic achievement at correlations of approximately r = .50–.70, and job performance at r = .20–.60 depending on job complexity.
These validity relationships did not emerge from a single study or a single test. They represent a convergence of findings across hundreds of independent investigations, using different tests, different populations, and different outcome measures. That cumulative evidence base is what gives professionally developed IQ scores their interpretive value.
Why is the norm sample so important?
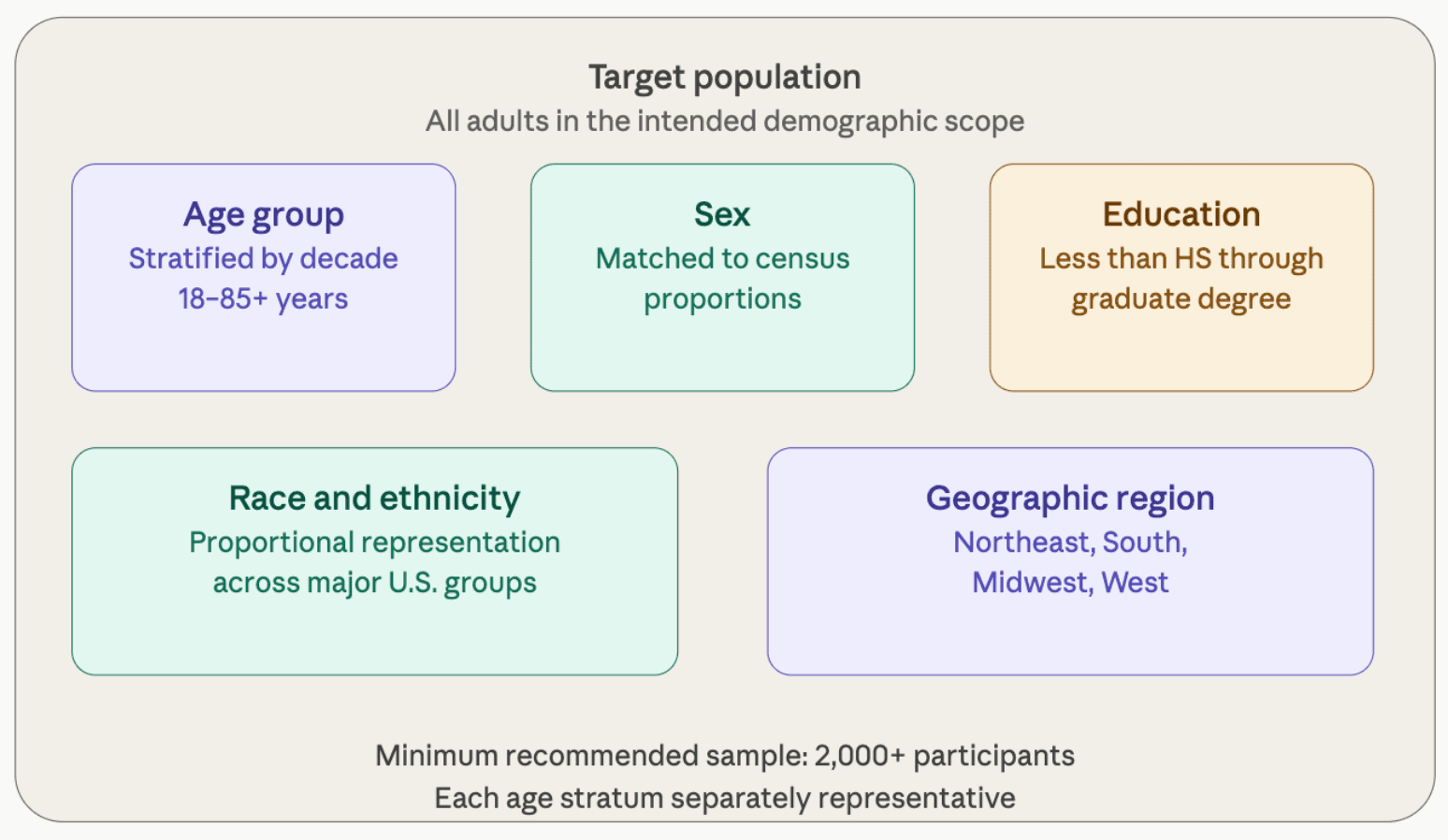
An IQ score is a relative measure. It tells an examinee where their performance falls in comparison to a reference group. That reference group is the norm sample — the group of people whose performance was used to calibrate the scoring system. Whether a score of 110 means "above average" or not depends entirely on how the norm sample performed. If the norm sample is not representative of the population the test is intended for, the scores will be systematically distorted.
This is one of the most common failure points for amateur online tests. When a test's norm group consists of the people who voluntarily sought out and paid for the test, the sample is self-selected. Self-selected samples are systematically biased toward people who are curious about their intelligence, which tends to skew scores toward higher ranges. An examinee whose score is compared against this kind of sample will almost always receive an inflated result.
What does the scoring system actually produce?
A professional IQ test does not produce a score simply by counting correct answers. Raw scores are transformed through a standardized procedure that compares an examinee's performance to the norm sample and expresses the result as a deviation IQ. This scoring system sets the population average at 100, with a standard deviation of 15. Approximately 68% of the population scores between 85 and 115, and about 95% score between 70 and 130.
Most professional tests also report subscores alongside the Full Scale IQ. These reflect the broader ability domains that CHC theory identifies — fluid reasoning, verbal comprehension, working memory, processing speed, and spatial ability. The RIOT reports scores for each of these domains in addition to a composite IQ, providing a detailed cognitive profile across six ability dimensions.
One essential concept in score interpretation is the standard error of measurement (SEM). Because every test has some degree of measurement error, no score is a precise fixed value. The SEM provides a range within which the true score is likely to fall. A score of 112 with a SEM of 3 means the examinee's true score is likely between approximately 109 and 115 with 68% confidence, or between 106 and 118 with 95% confidence. Professional test documentation always reports SEM values and confidence intervals for this reason.
How are test items screened for bias?
One of the most significant developments in professional test development since the 1960s is systematic screening of items for differential item functioning (DIF) — the statistical detection of items that perform differently across demographic groups for reasons unrelated to the ability being measured. An item shows DIF when examinees with the same underlying ability level but from different demographic groups have systematically different rates of correct response.
DIF screening is conducted during the piloting phase and often again after norm sample data is collected. Items that show meaningful DIF are revised or removed before the test is released. This is why modern professionally developed tests, when used on the populations they were designed for, show very little evidence of bias. The average score differences that exist across groups are not artifacts of biased items — they are real differences in performance that the test measures accurately. The existence of score differences between groups is not, by itself, evidence of bias; bias is a technical property that requires specific statistical investigation to establish.
What is the "indifference of the indicator"?
Charles Spearman made a counterintuitive observation that has proven enormously useful for test development: it does not matter much which tasks appear on an IQ test, as long as those tasks require thinking, reasoning, and judgment. He called this the "indifference of the indicator," andmodern research has confirmed it. Tests with very different content — vocabulary knowledge, matrix reasoning, spatial rotation, working memory — all measure general intelligence to a significant degree because they all load on g.
This principle has two practical consequences. First, test developers have genuine flexibility in choosing tasks, which allows them to select formats suited to their testing environment and target population. Second, it means that professional tests with different content can all contribute to a common research literature on intelligence. Findings from the Wechsler, the Stanford-Binet, the RIOT, and other instruments are mutually interpretable because they all measure the same underlying construct — even though the specific tasks differ considerably.
Where are professional IQ tests used?
Professional IQ tests are used across several high-stakes settings, and in each case the reason is the same: IQ scores provide valid, reliable, and actionable information about cognitive functioning that is not captured as efficiently by any other method.
In educational settings, psychologists use IQ tests as part of assessments for learning disabilities, giftedness identification, and educational placement decisions. In employment settings, cognitive ability tests are used for hiring and promotion decisions, most prominently in the military, where the Armed Services Vocational Aptitude Battery (ASVAB) functions as an IQ test and is used to identify candidates suited for specific roles. Research consistently finds that cognitive ability isone of the strongest predictors of job performance, particularly in roles requiring training and complex problem-solving.
In clinical settings, IQ tests serve multiple functions: as part of a diagnostic workup for neurological and psychiatric conditions, to establish cognitive baselines before treatment, and to identify cognitive impairments. In forensic settings — courts, prisons, parole hearings — IQ assessments are used to establish whether defendants are competent to stand trial, what level of care is appropriate, and whether certain punishments are applicable under law. Using an amateur test in any of these contexts is not simply ineffective — it is a potential source of harm to the person being assessed.
What does the test documentation look like?
A professional IQ test comes with a technical manual — a detailed document that describes every significant decision made during the test's development. This typically includes the theoretical framework, sample characteristics and collection procedures, item development and piloting methodology, reliability coefficients (internal consistency, test-retest), validity studies, norm tables organized by age, and scoring procedures. The manual is often restricted to qualified users rather than distributed publicly, but its existence should be verifiable and some summary documentation should be publicly accessible.
Some tests also publish research bulletins, technical updates, and peer-reviewed articles as the test accumulates an independent research record. The presence of a test in published peer-reviewed research is one of the clearest signals that independent scientists have found the test credible enough to use in their own work. A test that has never appeared in a scholarly publication has not been independently evaluated.
The first professional online IQ test
For most of the history of intelligence testing, professional assessments were administered individually, face-to-face, by trained clinicians. That arrangement is effective, but it limits access: the cost and logistical requirements of a clinical assessment put it beyond reach for most people who are simply curious about their cognitive profile.
TheReasoning and Intelligence Online Test (RIOT) represents a different model. It is the first online IQ test developed to meet all of the technical and ethical standards set out by the APA, AERA, and NCME. Built on the CHC theoretical model, the RIOT underwent expert content review, pilot testing, IRT-based item analysis, and norming on the first properly representative U.S.-based online sample. It also provides detailed subscores across six cognitive domains alongside a composite IQ.
The existence of a legitimate professional test available online does not change what separates professional tests from amateur ones. The same standards apply: theoretical grounding, documented reliability, validity evidence, representative norms, and named, credentialed creators who are accountable for their work. What the RIOT demonstrates is that meeting those standards is achievable in an online format — and that access to accurate cognitive assessment does not have to require a clinic appointment.
Parting thoughts
The difference between a professional IQ test and an amateur one is not subtle. Professional tests take years to develop, require specialized expertise at every stage, and produce scores whose interpretations are grounded in a decades-long research literature. Amateur tests, by contrast, are built quickly, without technical oversight, and produce numbers whose meaning cannot be verified.
Understanding what goes into a professional IQ test matters for anyone using IQ scores in consequential decisions — and for anyone who simply wants to know that the score they are looking at is measuring something real.