Jun 15, 2026·Accuracy, Reliability & Criticism
How Accurate Are IQ Tests?
Are online IQ scores actually correct? Discover the truth about test reliability, measurement error, and validity. Read the guide and try the RIOT test!
Asking whether IQ tests are accurate is a reasonable question, and the honest answer is: it depends on what you mean by "accurate," and it depends very much on which test is being discussed. For professionally developed tests used with the populations they were designed for, the evidence for accuracy is compelling and has been accumulating for over a century. For the tests most people actually encounter — free quizzes on the internet, quick assessments with no documented development process — the answer is far less encouraging.
This article lays out what psychologists actually mean when they talk about test accuracy, what the data show for professional IQ tests, and where the genuine limits of even the best tests lie.
Accuracy is not one thing
In everyday speech, "accurate" means something close to "correct" — a measurement that gives the right answer. In psychometrics, accuracy is a more complex concept that breaks down into three distinct components: reliability, validity, and freedom from measurement error. Each matters for different reasons, and a test can perform well on some while failing on others. The sections below address each in turn.
Reliability: how consistent are IQ scores?
Reliability refers to the consistency of scores: does the test produce similar results when the same person takes it under similar conditions on different occasions? The most commonly reported indicator is test-retest reliability — the correlation between scores obtained by the same group of people on two separate testing occasions.
For professionally developed IQ tests, this correlation is very high. Most professionally developed IQ tests achieve test-retest reliability between .80 and .95 with several weeks between testings. Studies of the Wechsler Adult Intelligence Scale find full-scale IQ test-retest correlations of approximately .90, with verbal and performance scores in a similar range — and these correlations remain high even across different clinical populations and testing intervals of up to 10 years.
Internal consistency — the degree to which the different items and subtests within a test all measure the same underlying construct — is similarly high. Modern intelligence tests achieve reliability coefficients exceeding .90 for composite scores, though individual subtest reliabilities tend to be somewhat lower, typically in the .80 range.
These numbers are high by the standards of psychological measurement. Many personality tests, clinical interviews, and behavioral rating scales operate with reliabilities in the .70s or lower. The fact that IQ tests consistently achieve reliability above .90 for composite scores reflects both the stability of intelligence as a trait and the quality of the development process behind professionally built tests.
It is worth noting that reliability is not uniform across all tests or all populations. Subtest scores are less reliable than composite scores, which is why professional test reports always include confidence intervals and why clinicians are cautious about over-interpreting differences between individual subtests. Research on the WISC-V, for example, found that while full-scale IQ and the verbal comprehension index both showed adequate long-term stability, subtest scores and intraindividual profile differences were far less stable over a 2.6-year interval — suggesting that only the composite IQ and a few index scores possess sufficient reliability for high-stakes clinical use. This is an important caveat that conscientious test users should keep in mind.
What measurement error actually means
Even a highly reliable test is not a perfect instrument. Every IQ score obtained on any single testing occasion contains some degree of random measurement error. This error arises from sources that are difficult or impossible to control completely: normal day-to-day variation in how a person feels, minor fluctuations in attention and concentration, and the fact that a finite set of test items is only a sample of all possible items that could measure the construct.
The standard error of measurement (SEM) quantifies this unavoidable uncertainty. It is derived directly from the test's reliability and the standard deviation of the score scale. For most professionally developed IQ tests with reliability coefficients around .95 and a standard deviation of 15, the SEM is approximately 3 to 5 IQ points.
The SEM is used to construct confidence intervals around an observed score. A 95% confidence interval equals the observed score ± 1.96 × SEM. For example, if a test has an SEM of 3 and a person scores 105, the 95% confidence interval is approximately 99–111, meaning there is 95% confidence that the person's true score falls within this range.
This has a practical implication that matters a great deal in applied settings. An IQ score of 115 is not the same as saying a person's true intelligence is exactly 115. It is more accurate to say their true ability is most likely somewhere in a range around 115, with the width of that range depending on the test's SEM. Reputable test reports — including those produced by the Reasoning and Intelligence Online Test — present scores alongside confidence intervals for precisely this reason. Treating any single IQ score as an exact, fixed value is a misuse of what the test can tell us.

One additional nuance: measurement precision is not uniform across the score range. Tests are typically calibrated to measure most precisely near the middle of the distribution, where most examinees fall. At the extremes — very high or very low IQ scores — precision decreases and confidence intervals widen. This is known as the conditional standard error of measurement, and it matters practically in contexts like intellectual disability determinations, where a few points can carry legal and clinical significance.
IQ stability over time
One of the strongest forms of evidence for the accuracy of IQ tests is that they produce scores that are remarkably stable across time. If IQ tests were capturing mostly noise or temporary states, scores would fluctuate substantially when a person was retested years or decades later. They do not.
Longitudinal research consistently shows that individual differences in intelligence are highly stable across the lifespan. Studies report correlations of 0.86–0.89 when comparing childhood to young-adult Wechsler scores, and stability coefficients in the 0.70–0.90 range across multi-year intervals are common in the research literature. The remarkable Scottish Mental Survey study, which tested nearly the entire population of Scottish 11-year-olds in 1932 and then retested survivors in their 70s and 80s, found a stability coefficient of .63 between age 11 and age 77 — a 66-year interval — rising to .73 after correction for range restriction.
These correlations would be impossible to achieve if IQ tests were simply measuring test-taking behavior, momentary focus, or cultural familiarity. They reflect a genuine underlying cognitive trait that persists across the lifespan.
That said, there is an important distinction between rank-order stability and absolute score change. Rank-order stability means that a person who scores in the top quarter of the distribution at age 12 tends to also score in the top quarter at age 40. It does not mean their raw performance on identical test items stays the same. In childhood especially, the cognitive abilities that IQ tests measure are developing rapidly, and there is real variability in how that development unfolds. IQ scores in early childhood are less stable than scores obtained after age 8 or so, and stability tends to increase as children get older.
Does what happens during testing affect accuracy?
People often worry that factors like nervousness, a bad night of sleep, or an unfamiliar environment might substantially distort their IQ score. The research on this is somewhat reassuring.
Intelligence is generally stable over time, and performance on an intelligence test can be influenced by psychological processes including motivation and attention. However, the effects of many commonly feared factors are smaller than people expect. A 2025 study that induced acute stress in participants before an IQ test found that neither test anxiety nor stress had a statistically significant effect on composite IQ scores. The stability of IQ scores under conditions of moderate stress is a feature of good test design, not an accident.
What does affect scores more meaningfully is low motivation or deliberate low effort. An examinee who does not try, or who is completely disengaged, will produce a score that underestimates their true ability. This is one reason why professional test administrators are trained to establish rapport, explain the purpose of the test, and monitor engagement during administration. For self-administered online tests, motivation becomes the examinee's own responsibility — a reason to approach the testing session with the same focus one would bring to any serious cognitive task.
The effects of genuine illness, extreme fatigue, or significant psychological distress are more substantial. Psychologists who administer tests in person are trained to note and document these conditions and to exercise caution in interpreting scores obtained under such circumstances. The professional standard is to note any unusual testing conditions in the report and to consider whether retesting may be appropriate.
Validity: does an IQ score measure intelligence?
Reliability establishes that IQ tests produce consistent scores. Validity addresses the harder question of whether those scores measure what they are supposed to measure — general cognitive ability — and whether they produce useful predictions in the real world.
The evidence for validity is extensive and comes from multiple independent lines of research. Factor-analytic studies consistently show that performance across diverse cognitive tasks is positively intercorrelated — exactly what general intelligence theory predicts. IQ scores also correlate meaningfully with biological variables including brain volume, neural processing efficiency, and reaction time. These biological correlates would be very difficult to explain if IQ scores were capturing only test-taking skill or educational exposure rather than genuine cognitive capacity.
The most practically important form of validity evidence — criterion validity — examines whether IQ scores predict outcomes that intelligence theory says they should predict. Here the evidence is particularly strong. IQ correlates approximately .50 to .70 with academic achievement across educational levels. The landmark meta-analysis by Schmidt and Hunter found general cognitive ability to be the strongest single predictor of job performance across occupational categories. IQ also predicts health outcomes and longevity with consistent reliability.
It is important to add a qualification that researchers themselves have raised. Validity does not mean perfect prediction. Even a validity coefficient of .50 leaves half the variance in outcomes unexplained. Intelligence is one important determinant of many life outcomes, but it shares those outcomes with personality, effort, socioeconomic context, opportunity, and chance. What validity evidence shows is that IQ tests measure something real and that this something matters — not that IQ determines outcomes in isolation.
Accuracy varies sharply by test type
Everything said above about reliability, SEM, stability, and validity applies specifically to professionally developed IQ tests. The picture is dramatically different for the amateur tests that make up the vast majority of what is available online.
A professionally developed test undergoes years of development. Items are piloted, analyzed statistically, and revised or discarded. A representative norm sample is assembled. Reliability coefficients are calculated. Validity evidence is gathered through external criterion studies. All of this is documented in a technical manual. This process is what produces the reliability coefficients above .90 and the decades of criterion validity evidence.
An amateur test has none of this. There is no pilot testing, no item analysis, no representative norm sample, and no validity evidence. The creator has no way of knowing whether the items work, whether the scoring is calibrated correctly, or whether the resulting scores have any meaningful relationship with actual cognitive ability. The scores such a test produces are, in a technical sense, arbitrary.
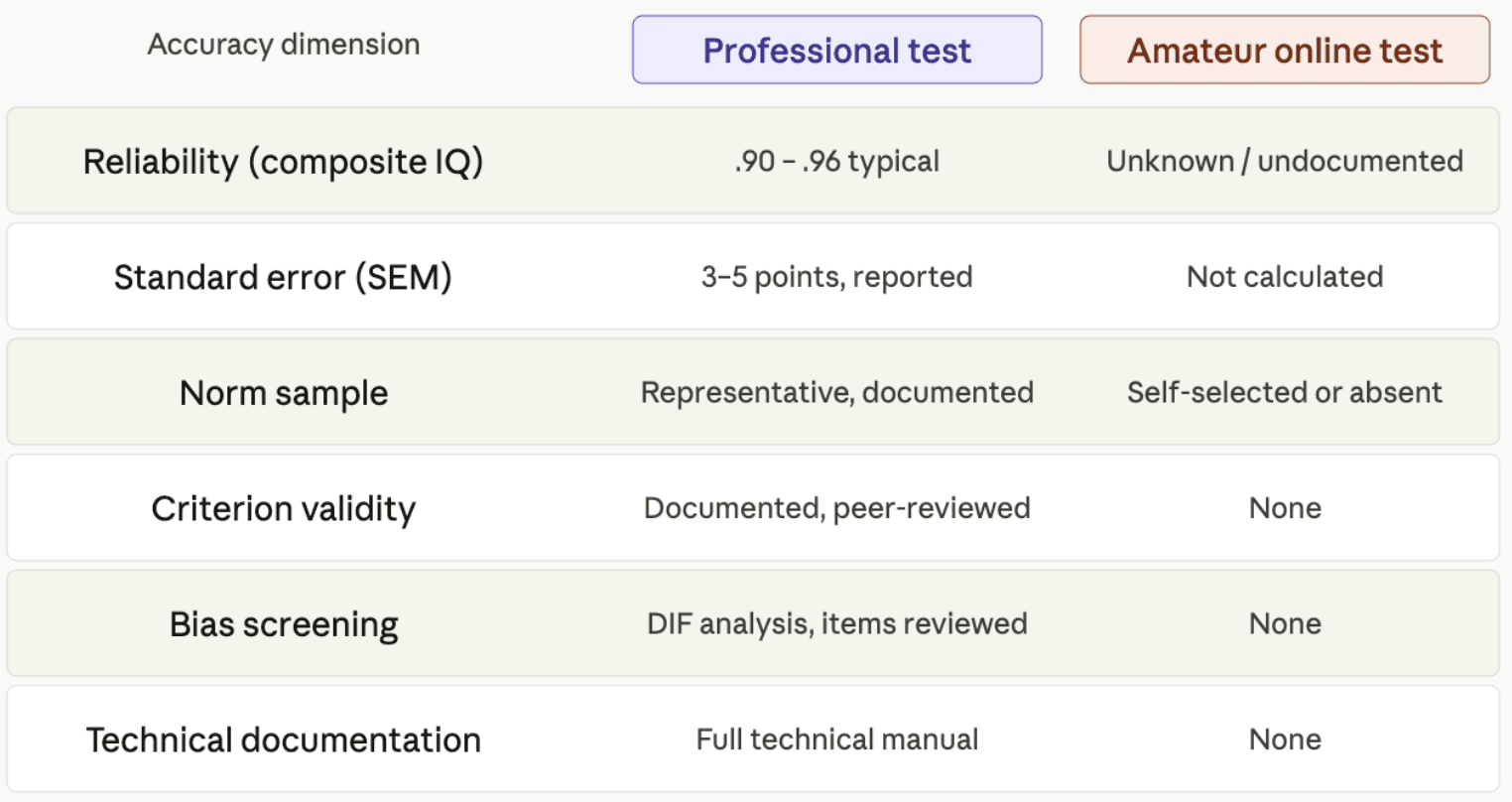
The score inflation problem
One consequence of missing norm samples deserves its own treatment. The accuracy of a score depends not only on whether the test items work, but on whether the norm sample against which scores are compared is representative of the intended population.
Most amateur online IQ tests are either completely without a norm sample or use a self-selected sample of internet users who chose to take the test. This group is not representative of the general population. People who seek out online IQ tests tend to be more educated, more curious, and likely higher in IQ than average. When a new examinee's score is compared against this inflated reference group, an average person looks above average relative to the skewed comparison group, and the test systematically reports elevated scores to flatter test-takers — which is, not coincidentally, good for selling detailed score reports.
This is why so many free online IQ tests report scores in the 120s and 130s for a population that, by definition, must average around 100. The problem is not that people are measuring higher than expected. The problem is that the measurement is simply wrong.
Where even professional tests have limits
Accuracy has scope limits that apply even to the best-developed instruments. Professional IQ tests are accurate within defined boundaries, and part of what professional development involves is being explicit about what those boundaries are.
IQ tests measure cognitive ability as defined by scientific theory — reasoning, working memory, processing speed, crystallized knowledge, and related abilities. They do not comprehensively measure creativity. They do not measure determination, interpersonal judgment, moral character, or the ability to navigate complex social environments. Intelligence matters for a wide range of outcomes, but no single score can summarize a person's full cognitive and non-cognitive makeup.
Accuracy also depends on the test being used with the population it was designed for. A test developed and normed on English-speaking American adults is not automatically accurate for children, for speakers of other languages, or for people from cultures with different testing traditions. Professional test creators are explicit about the intended populations for their instruments. The accuracy claims attached to a test apply only within those boundaries.
How to identify a test that is actually accurate
Given everything above, there are a few concrete criteria that distinguish a test likely to produce accurate scores from one that is not.
The author's identity and credentials should be publicly stated. Professional test creators are accountable for the quality of their work and take pride in attaching their names to it. Anonymous tests have no accountability mechanism and no professional reputation at stake.
Reliability data should be reported. A professionally developed test will state its internal consistency and test-retest reliability coefficients in its documentation. If no reliability data are available anywhere, there is no basis for trusting the scores.
The norm sample should be described in detail. Its size, demographic composition, and the methodology used to recruit it should all be documented. A test that does not disclose its norm sample cannot demonstrate that its scores have meaningful reference points.
Validity evidence should exist in the form of peer-reviewed research. Searching for the test's name in Google Scholar is an effective quick check. If nothing appears, the test has not been evaluated by independent scientific experts.
These are the same criteria the Reasoning and Intelligence Online Test meets — developed by a named researcher with over 15 years of published work in intelligence research, normed on a representative U.S. sample, and built to comply with the professional standards established by the American Educational Research Association, the American Psychological Association, and the National Council on Measurement in Education. For an online test, that level of rigor is genuinely unusual, and it is what produces scores that are actually accurate in the technical sense of the word.
Sources
- Schmidt, F. L., & Hunter, J. E. (1998). The validity and utility of selection methods in personnel psychology. Psychological Bulletin, 124(2), 262–274. https://doi.org/10.1037/0033-2909.124.2.262
- Warne, R. T. (2025). Technical manual for the Reasoning and Intelligence Online Test, version 1.0. RIOT IQ.
- Matarazzo, J. D., & Herman, D. O. (1984). Base rate data for the WAIS-R: Test-retest stability and VIQ–PIQ differences. Journal of Clinical Neuropsychology, 6(4), 351–366. https://doi.org/10.1080/01688638408401228
- Watkins, M. W., et al. (2022). Long-term stability of WISC-V scores in a clinical sample. PMC. https://pmc.ncbi.nlm.nih.gov/articles/PMC8967112/
- Lord, F. M., & Novick, M. R. (1968). Statistical theories of mental test scores. Addison-Wesley.
- Deary, I. J., Whalley, L. J., Lemmon, H., Crawford, J. R., & Starr, J. M. (2000). The stability of individual differences in mental ability from childhood to old age. Intelligence, 28(1), 49–55. https://doi.org/10.1016/S0160-2896(99)00031-8
- Whalley, L. J., & Deary, I. J. (2001). Longitudinal cohort study of childhood IQ and survival up to age 76. BMJ, 322(7290), 819. https://doi.org/10.1136/bmj.322.7290.819
- Bouchard, T. J., Jr. (2013). The Wilson effect: The increase in heritability of IQ with age. Twin Research and Human Genetics, 16(5), 923–930. https://doi.org/10.1017/thg.2013.54
- Koenig, K. A., Frey, M. C., & Detterman, D. K. (2008). ACT and general cognitive ability. Intelligence, 36(2), 153–160. https://doi.org/10.1016/j.intell.2007.03.005
- American Educational Research Association, American Psychological Association, & National Council on Measurement in Education. (2014). Standards for educational and psychological testing. AERA. https://www.testingstandards.net/
- Duckworth, A. L., Quinn, P. D., Lynam, D. R., Loeber, R., & Stouthamer-Loeber, M. (2011). Role of test motivation in intelligence testing. PNAS, 108(19), 7716–7720. https://doi.org/10.1073/pnas.1018601108
- Deary, I. J., Strand, S., Smith, P., & Fernandes, C. (2007). Intelligence and educational achievement. Intelligence, 35(1), 13–21. https://doi.org/10.1016/j.intell.2006.02.001
- Colom, R., & Thompson, P. M. (2011). Understanding human intelligence by imaging the brain. In Chamorro-Premuzic et al. (Eds.), The Wiley-Blackwell handbook of individual differences. Wiley.
- Strenze, T. (2007). Intelligence and socioeconomic success: A meta-analytic review of longitudinal research. Intelligence, 35(5), 401–426. https://doi.org/10.1016/j.intell.2006.09.004
- Schuerger, J. M., & Witt, A. C. (1989). The temporal stability of individually tested intelligence. Journal of Clinical Psychology, 45(2), 294–302. https://doi.org/10.1002/1097-4679(198903)45:2<294::AID-JCLP2270450219>3.0.CO;2-L
Take our professional IQ test
Want to know your IQ? Try the first ever professional online IQ test.
Article Categories
All ArticlesUnderstanding IQ ScoresTaking an IQ TestRIOT-Specific InformationGeneral IQ & IntelligenceAdvanced Topics & ResearchIQ Scores & InterpretationMensa & High-IQ SocietiesOnline IQ Tests IQ Test Basics & FundamentalsAverage IQ & DemographicsFamous People & IQHistory & Origins Of IQ TestingAccuracy, Reliability & CriticismSpecial Population & Related ConditionsImproving IQ / PreparationSpecific IQ Tests & FormatsIQ Testing for HR & RecruitmentSkills Assessment
Related Articles
What Is the Average IQ in the UK?Is Gen Z IQ Dropping?How to Tell If an Online IQ Test Is LegitimateWhy a Norm Sample Matters for IQ Test AccuracyCan Amateur IQ Tests Give Accurate Scores?How Accurate Are IQ Tests?What Is an IQ Confidence Interval? Why Scores Are Ranges7 Common Myths About IQ Tests DebunkedWhat Makes an IQ Test Scientifically Valid?Are IQ Tests Racist?Are IQ Tests Biased?How Reliable are IQ Tests?The IQ of Artificial IntelligenceChatGPT’s IQWhy Are IQ Tests Flawed?Are Online IQ Tests Legit?Is There an Official IQ Test?What is the Most Accurate IQ Test?Are IQ Tests Valid?Are IQ Tests Reliable?Are IQ Tests Good Measures of Intelligence?Are IQ Tests Accurate?
Take our IQ testsCompare all tests
Basic IQ Test
5 subtests + 5 cognitive abilities
Features
- ~13 Minutes
- IQ score
- Cognitive abilities breakdown
- ±5.6 IQ margin of error
5/15 Subtests
Learn moreVocabulary
Matrix Reasoning
SToVeS
Visual Reversal
Symbol Search
Full IQ Test
15 subtests + all cognitive abilities
Features
- ~52 Minutes
- IQ score
- Cognitive abilities breakdown
- ±3.7 IQ margin of error
15/15 Subtests
Learn moreVocabulary, Information, Analogies
Matrix Reasoning, Visual Puzzles, Figure Weights
Object Rotation, SToVeS, Spatial Orientation
Computation Span, Exposure Memory, Visual Reversal
Symbol Search, Abstract Matching
Simple Reaction Time, Choice Reaction Time
Community
Intelligence Journals & Organizations
Our Articles