Jun 15, 2026·Advanced Topics & Research
The Science Behind IQ Tests: Understanding Intelligence Assessment
Discover the science of intelligence assessment, from norming to the CHC model. Learn how scores are calculated and try the professional RIOT IQ test!
People interact with the phrase "IQ test" constantly — in news articles, job applications, school evaluations, and casual conversation. Yet most people have only a vague sense of what an IQ test actually is, what it measures, and why its results are meaningful. That gap between familiarity and understanding is worth closing. IQ tests are among the most carefully constructed and rigorously validated instruments in all of psychological science. Understanding the science behind them is the first step to understanding what IQ scores actually mean.
This article explains how IQ tests are built, how scores are calculated, and why the process matters — both for interpreting results and for distinguishing tests worth taking from tests that aren't.
What is intelligence, and how can it be measured?
Before discussing IQ tests, it is worth being clear about what intelligence is. According to a 1997 consensus statement signed by over 50 leading intelligence researchers, intelligence is "a very general mental capability that, among other things, involves the ability to reason, plan, solve problems, think abstractly, comprehend complex ideas, learn quickly and learn from experience." That definition aligns closely with how most people intuitively understand the word.
The measurement challenge is that intelligence cannot be directly observed. It must be inferred from performance. This is not unique to psychology — blood pressure, air quality, and structural stress are all inferred through instruments that translate an underlying property into a number. An IQ test does the same thing: it gives people a series of tasks that require reasoning, judgment, and problem solving, and it converts their performance into a score.
The score is called an IQ, short for "intelligence quotient" — a term that originated in an early scoring formula but has since outlived that formula. Today, the term simply refers to the number produced by a properly standardized intelligence test.
One of the most important and often overlooked findings in intelligence research is that it does not matter very much which specific tasks appear on an IQ test. As long as the tasks require genuine thinking, reasoning, or judgment, they will measure intelligence. Charles Spearman called this principle "the indifference of the indicator," and modern research has consistently confirmed it. This is why wildly different tests — from pattern completion tasks to vocabulary tasks to logical puzzles — all tend to measure the same underlying ability.
The theoretical foundation: the CHC model
Professional IQ tests are not assembled arbitrarily. They are built on a theoretical understanding of what intelligence is and how cognitive abilities are structured. The dominant framework today is the Cattell-Horn-Carroll (CHC) theory, which organizes human cognitive abilities into a three-level hierarchy.
At the top of the hierarchy is g, or general intelligence — the broad mental capacity that Spearman identified in 1904 and that predicts performance across an enormous range of tasks. Below g sits a tier of broad abilities — fluid reasoning, crystallized intelligence, working memory, processing speed, spatial reasoning, and several others. Each of these broad abilities, in turn, breaks down into narrower, more specific cognitive skills.
The CHC theory did not arrive fully formed. It took decades of research to develop. Raymond Cattell and John Horn established the foundational distinction between fluid intelligence (the ability to solve novel problems) and crystallized intelligence (accumulated knowledge and verbal ability) in the 1960s. John Carroll then conducted a landmark reanalysis of over 400 datasets spanning 70 years of psychometric research, published in 1993, which confirmed and extended the hierarchical structure. The synthesis of these traditions into CHC theory is what currently guides the development of modern intelligence tests.
Most professional IQ tests — including the Wechsler scales, the Woodcock-Johnson, and the Reasoning and Intelligence Online Test (RIOT) — are built around this framework. It is the reason that these tests report both an overall IQ and a set of subscores: the overall IQ captures g, while the subscores reflect the broad CHC abilities.
How IQ tests are developed
The development of a professional IQ test is a multi-year, multi-stage process governed by strict technical and ethical standards. Before I began creating the Reasoning and Intelligence Online Test, I spent 15 years studying human intelligence, publishing peer-reviewed research on the topic, and learning the science of test development — called psychometrics. The work that goes into a professional test is substantial. Here is what that process actually involves.
Theoretical grounding. Every professional test begins with a theory. The theory determines which cognitive abilities the test will measure, how many subtests it will contain, what kinds of tasks will appear, and how the scores will be interpreted. Without a theoretical foundation, a test is just a collection of puzzles with no principled basis for interpreting the scores.
Task selection and item writing. Test creators select tasks that measure the target abilities and write individual items (questions or puzzles) for each task. This requires both content expertise and knowledge of how different item formats behave psychometrically. Items that seem good on the surface can fail in practice — being too easy, too hard, too ambiguous, or unfairly advantageous to specific groups.
Pilot testing and item analysis. Before any item appears on a final test, it is administered to a pilot sample and subjected to statistical analysis. Item response theory and classical test methods are used to evaluate each item's difficulty, discriminating power, and potential bias. Items that fail these analyses are revised or eliminated. This process is iterative and can require multiple rounds of revision.
Norming. The final test is administered to a representative sample of the intended test-taking population — called the norm sample. When an examinee takes the test, their raw performance is compared against the norm sample to determine how their performance ranks relative to the population. This is why representativeness matters: a biased norm sample produces distorted scores.
Bias review. At multiple stages — both during item development and during norming — items are reviewed for differential item functioning (DIF). DIF analysis identifies items that function differently across demographic groups in ways unrelated to the trait being measured. Items that show DIF are revised or removed.
Documentation and standards compliance. The entire development process is documented in a technical manual, which provides the statistical and methodological evidence that the test meets professional standards. The relevant guidelines in the United States are established by the American Educational Research Association, the American Psychological Association, and the National Council on Measurement in Education, published as the Standards for Educational and Psychological Testing.

How IQ scores are calculated
When an examinee completes an IQ test, their raw performance (the number of questions answered correctly, the time taken, or a combination) is converted into a standardized score. This conversion relies on the norm sample that was collected during development.
The raw score is compared against the distribution of scores in the norm group for the examinee's age. This produces a deviation IQ — a score that expresses how far above or below the average the examinee performed, in standard deviation units, which are then scaled to a familiar metric.
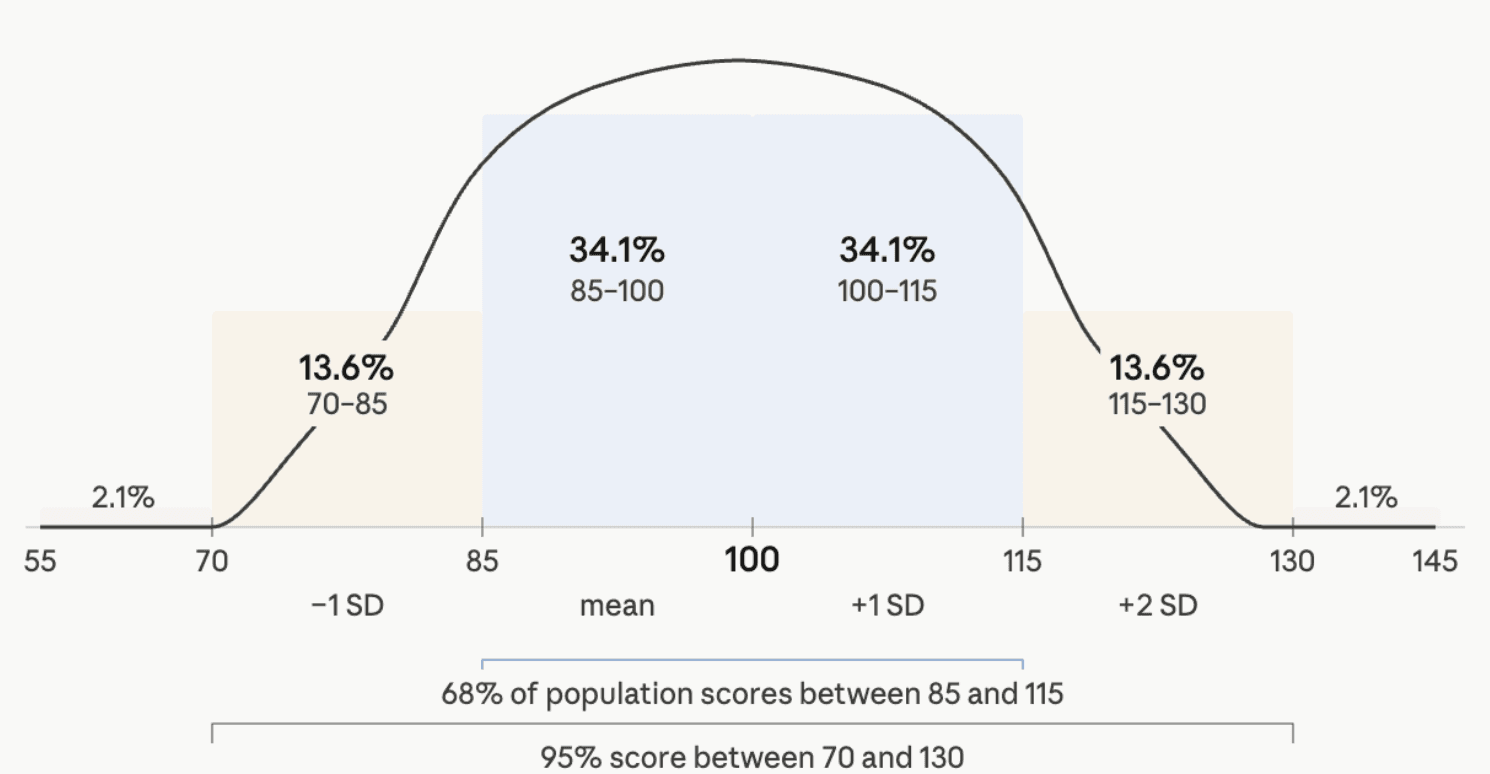
Most professional IQ tests use a scale with an average (mean) of 100 and a standard deviation of 15. This means that a score of 100 represents exactly average performance for an examinee's age group. A score of 115 is one standard deviation above average — higher than approximately 84% of the population. A score of 85 is one standard deviation below average. About 68% of all scores fall between 85 and 115, and 95% fall between 70 and 130.
One point that is frequently misunderstood: an IQ score is not a percentage correct. A person who scores 80 on an IQ test did not answer 80% of the questions correctly. The score is a relative measure — it says where a person stands compared to others their age, not how many items they got right.
Reliability: what it means and why it matters
In psychometrics, "reliability" refers to the consistency of test scores. A reliable IQ test produces similar scores when the same person takes it under similar conditions on different occasions. This is critical because intelligence is believed to be a relatively stable trait — it does not swing dramatically from day to day. If an IQ test is unreliable, its scores are heavily contaminated by random error, making them difficult to interpret.
Psychologists assess reliability in several ways. Test-retest reliability measures whether scores are consistent when the same person takes the same test twice, weeks or months apart. Internal consistency reliability measures whether the different items on a test are all measuring the same underlying construct. Both are important, and both are reported in the technical documentation of professional tests.
Modern intelligence tests achieve reliability coefficients exceeding .90 for composite scores, though individual subtest scores tend to be somewhat lower. Most professionally developed IQ tests achieve test-retest reliability between .80 and .95 with several weeks between testings — a range that is considered excellent in psychological measurement. Tests with reliabilities in this range produce scores where the observed score is a good approximation of the person's true underlying level of ability.
Reliability is a property of scores, not of the test itself. This is an important technical distinction. A test can produce highly reliable scores for one population and less reliable scores for another. Professional test creators study reliability for the specific populations their tests are intended to serve.
One consequence of imperfect reliability is measurement error. No test, however well constructed, produces a perfectly accurate score. Every IQ score has a standard error of measurement — a range around the observed score that reflects the expected variability if the same person took the test many times. A proper score report from a professional test includes a confidence interval that communicates this uncertainty. It is more accurate to say that an examinee's true IQ falls within a certain range than to treat a single score as an exact number.
Validity: do scores mean what we think they mean?
Reliability is necessary but not sufficient for a useful test. A test can produce consistent scores that consistently measure the wrong thing. Validity — evidence that the test scores measure what they are intended to measure and can be used for the purposes claimed — is the central question in test evaluation.
Validity is assessed in several ways. Construct validity examines whether the test actually measures the intended cognitive constructs. Factor-analytic evidence is particularly important here: if the test is designed around CHC theory, the statistical structure of the scores should conform to the theoretical model. Content validity examines whether the tasks on the test adequately represent the abilities they are supposed to measure. Criterion validity — the most practically important form — examines whether the scores predict outcomes that intelligence theory says they should predict.
The criterion validity evidence for IQ is among the strongest in psychology. IQ correlates approximately .50 to .70 with academic achievement across educational levels. Schmidt and Hunter's landmark 1998 meta-analysis found that general cognitive ability is the single best predictor of job performance, with validity coefficients ranging from about .30 for low-complexity jobs to higher values for complex, cognitively demanding work. IQ also predicts health outcomes, income, and longevity with meaningful consistency. These are not the correlations of a test measuring nothing — they reflect a real and consequential underlying ability.
It is important to add that validity is always specific to a purpose and a population. A test score's validity for one use does not guarantee validity for a different use. Professional test creators are explicit about which uses are and are not supported by evidence. Claims that a test is simply "valid" without specifying for what purpose are scientifically imprecise.
What a battery structure adds
Many professional IQ tests are batteries — collections of multiple subtests that each measure a different cognitive ability. This structure has a clear advantage: by sampling broadly across the cognitive ability hierarchy, a battery produces scores that are more comprehensive and more nuanced than what any single task could provide.
A well-constructed battery reports an overall IQ as well as scores for the broad abilities in the second tier of the CHC hierarchy. These index scores give meaningful insight into a person's cognitive profile that a single number cannot. Two people can have the same overall IQ while having quite different profiles of strengths and weaknesses. That information is clinically and practically useful.
This is one of the reasons that single-format tests, while useful in some contexts, cannot fully replace a battery. The Raven's Progressive Matrices, for example, is an excellent measure of fluid reasoning, but a score on the Raven's tells an examiner relatively little about verbal ability, working memory, or processing speed. A full battery covers all of these.
Norm samples: the hidden foundation of every IQ score
Every IQ score is a relative comparison. The question an IQ score answers is not "how many items did this person answer correctly?" but rather "how does this person's performance compare to the population the test was designed for?" That comparison is only meaningful if the norm sample is a good representation of that population.
The norm sample must accurately reflect the target population and must be sufficiently large to reduce the standard errors of the normative data to negligible proportions. Professional test manuals document the demographic composition of the norm sample — including age, sex, educational background, race and ethnicity, and geographic distribution — and explain the methodology used to recruit it.
A self-selected norm sample is a significant problem. If the only people who were normed are those who voluntarily sought out and paid for a test, they are almost certainly not representative of the general population. They are likely to be more educated, more motivated, and higher in IQ than average. Comparing a new examinee's score against such a sample would systematically overestimate how high the examinee scored relative to the actual general population.
This is one of the most common and consequential failures in online IQ testing. Websites that report scores without a documented, representative norm sample cannot produce meaningful IQ scores — they can only rank examinees against whoever happened to take the test, which tells you very little.
Bias screening: a standard part of professional development
Given that IQ tests show average differences across demographic groups — by sex, race, education, and other characteristics — a natural question arises: are IQ tests biased? This is a question the field has taken seriously for decades.
It is important to distinguish between two different uses of the word "bias." In everyday language, "bias" often means "unfair" or "offensive." In psychometrics, it has a specific technical definition: a test is biased if one group has a systematic advantage or disadvantage on the test for reasons unrelated to the ability being measured. The existence of average score differences between groups is not, by itself, evidence of bias. A test can show group differences and still be unbiased.
Since the 1980s, professional test creators have used DIF analysis to screen items for bias before releasing a test. Items that show DIF are revised or removed. The accumulated evidence from decades of bias research shows that professionally developed IQ tests administered to the populations they were designed for are not meaningfully biased. Expert reviews and bias studies have consistently reached this conclusion.
What separates a professional test from an amateur one
Given everything described above — the theoretical grounding, the piloting, the norming, the reliability studies, the validity evidence, the bias screening, the technical documentation — it should be clear that professional test development is a substantial undertaking. It requires years of training in psychometrics, access to large and representative participant samples, statistical expertise, and peer review.
Amateur tests lack all of this. A test created by a non-expert, regardless of how polished it appears, cannot provide accurate IQ scores. There is no norm sample, no reliability data, no validity evidence, no bias screening. The score it produces is essentially arbitrary.
 There are a few markers that reliably distinguish professional IQ tests from amateur ones. A professional test has a named, credentialed author who is publicly accountable for its quality. It has documented technical properties — reliability coefficients, validity studies, factor-analytic evidence. It has a representative norm sample with stated demographics and methodology. It is aligned with a recognized scientific theory of intelligence. And it has been used in peer-reviewed research, which means it has been evaluated by independent scientific experts.
There are a few markers that reliably distinguish professional IQ tests from amateur ones. A professional test has a named, credentialed author who is publicly accountable for its quality. It has documented technical properties — reliability coefficients, validity studies, factor-analytic evidence. It has a representative norm sample with stated demographics and methodology. It is aligned with a recognized scientific theory of intelligence. And it has been used in peer-reviewed research, which means it has been evaluated by independent scientific experts.
There are a few markers that reliably distinguish professional IQ tests from amateur ones. A professional test has a named, credentialed author who is publicly accountable for its quality. It has documented technical properties — reliability coefficients, validity studies, factor-analytic evidence. It has a representative norm sample with stated demographics and methodology. It is aligned with a recognized scientific theory of intelligence. And it has been used in peer-reviewed research, which means it has been evaluated by independent scientific experts.Searching for a test's name in Google Scholar is a quick way to check whether the test has a peer-reviewed research record. If a search returns nothing, that absence is informative. Legitimate tests accumulate a research record over time.
What IQ scores predict
The most common objection to IQ testing is that the scores are "just a number" — that they do not reflect anything meaningful about real-world functioning. The evidence does not support this view. IQ scores are among the strongest and most consistently replicated predictors in all of social science.
IQ predicts academic achievement with correlations of approximately .50 to .70 across educational levels. It predicts occupational attainment, job performance, income, and health outcomes with more modest but meaningful correlations. Research by Strenze (2007) synthesizing longitudinal studies with an average combined sample of nearly 100,000 people found IQ to be the strongest predictor of education level, occupational status, and income — stronger than parental socioeconomic status or other measured factors.
These are probabilistic relationships, not deterministic ones. IQ does not guarantee any particular outcome. But it is a consistent predictor of outcomes that matter, which is precisely why it is used in educational diagnosis, clinical assessment, employment selection, and research.
A note on what IQ tests do not measure
Honesty about the limits of IQ tests is part of good science. IQ tests measure cognitive ability — reasoning, memory, processing speed, verbal knowledge, and related skills. They do not measure creativity in a comprehensive sense. They do not measure motivation, conscientiousness, interpersonal skill, leadership, or the many other non-cognitive characteristics that determine how well someone performs in the real world.
This does not diminish what IQ tests measure; it contextualizes it. An IQ score is genuinely informative about cognitive ability. It tells an examiner something real and useful. What it does not do is tell the whole story about a person's potential or likely outcomes. A high IQ is a tailwind. It opens doors. But it cannot force anyone through them.
What makes the RIOT different
The Reasoning and Intelligence Online Test (RIOT) is the first online IQ test developed to meet the same professional standards as traditional in-person assessments. It was developed by me after more than 15 years of intelligence research. The RIOT is built on the CHC model, includes multiple subtests measuring a range of broad cognitive abilities, underwent expert review by specialists from cognitive, educational, and developmental psychology, and was normed on a representative U.S. sample — the first time an online IQ test has been properly normed in this way.
Its development meets the standards established by the American Educational Research Association, the American Psychological Association, and the National Council on Measurement in Education. Items were screened for bias before release. Reliability and validity data are documented and available.
The result is an online assessment that produces the kind of accurate, interpretable, and defensible scores that have historically only been available through in-person assessment — now accessible at a fraction of the cost and without the need to schedule time with a clinician.
Sources
- Gottfredson, L. S. (1997). Mainstream science on intelligence: An editorial with 52 signatories, history, and bibliography. Intelligence, 24(1), 13–23. https://doi.org/10.1016/S0160-2896(97)90011-8
- Colom, R., & Thompson, P. M. (2011). Understanding human intelligence by imaging the brain. In T. Chamorro-Premuzic, S. von Stumm, & A. Furnham (Eds.), The Wiley-Blackwell handbook of individual differences. Wiley.
- Carroll, J. B. (1993). Human cognitive abilities: A survey of factor-analytic studies. Cambridge University Press. https://doi.org/10.1017/CBO9780511571312
- Schneider, W. J., & McGrew, K. S. (2018). The Cattell-Horn-Carroll theory of cognitive abilities. In D. P. Flanagan & E. M. McDonough (Eds.), Contemporary intellectual assessment: Theories, tests, and issues (4th ed., pp. 73–163). Guilford Press.
- Keith, T. Z., & Reynolds, M. R. (2010). Cattell-Horn-Carroll abilities and cognitive tests: What we've learned from 20 years of research. Psychology in the Schools, 47(7), 635–650.
- Schmidt, F. L., & Hunter, J. E. (1998). The validity and utility of selection methods in personnel psychology: Practical and theoretical implications of 85 years of research findings. Psychological Bulletin, 124(2), 262–274. https://doi.org/10.1037/0033-2909.124.2.262
- Strenze, T. (2007). Intelligence and socioeconomic success: A meta-analytic review of longitudinal research. Intelligence, 35(5), 401–426. https://doi.org/10.1016/j.intell.2006.09.004
- American Educational Research Association, American Psychological Association, & National Council on Measurement in Education. (2014). Standards for educational and psychological testing. AERA. https://www.testingstandards.net/
- Deary, I. J., Strand, S., Smith, P., & Fernandes, C. (2007). Intelligence and educational achievement. Intelligence, 35(1), 13–21. https://doi.org/10.1016/j.intell.2006.02.001
- Spearman, C. (1904). "General intelligence," objectively determined and measured. American Journal of Psychology, 15(2), 201–292. https://doi.org/10.2307/1412107
- Ree, M. J., Earles, J. A., & Teachout, M. S. (1994). Predicting job performance: Not much more than g. Journal of Applied Psychology, 79(4), 518–524. https://doi.org/10.1037/0021-9010.79.4.518
- Hunter, J. E., & Hunter, R. F. (1984). Validity and utility of alternative predictors of job performance. Psychological Bulletin, 96(1), 72–98. https://doi.org/10.1037/0033-2909.96.1.72
- Reynolds, C. R., & Suzuki, L. A. (2013). Bias in psychological assessment: An empirical review and recommendations. In J. R. Graham, J. A. Naglieri, & I. B. Weiner (Eds.), Handbook of psychology: Assessment psychology (2nd ed., Vol. 10, pp. 82–113). Wiley.
- Warne, R. T. (2025). Technical manual for the Reasoning and Intelligence Online Test, version 1.0. RIOT IQ.
- Salgado, J. F., Moscoso, S., & Berges, A. (2013). Meta-analysis of the validity of general mental ability for five performance criteria: Hunter and Hunter (1984) revisited. Frontiers in Psychology. https://doi.org/10.3389/fpsyg.2019.02227
Take our professional IQ test
Want to know your IQ? Try the first ever professional online IQ test.
Article Categories
All ArticlesUnderstanding IQ ScoresTaking an IQ TestRIOT-Specific InformationGeneral IQ & IntelligenceAdvanced Topics & ResearchIQ Scores & InterpretationMensa & High-IQ SocietiesOnline IQ Tests IQ Test Basics & FundamentalsAverage IQ & DemographicsFamous People & IQHistory & Origins Of IQ TestingAccuracy, Reliability & CriticismSpecial Population & Related ConditionsImproving IQ / PreparationSpecific IQ Tests & FormatsIQ Testing for HR & RecruitmentSkills Assessment
Related Articles
Does High IQ Actually Correlate With Higher Salary After Age 30?High IQ vs. High EQ: Which One Predicts Long-Term Relationship Happiness?Are You Left-Brained or Right-Brained? What Neuroscience Actually SaysWhat Does Too Much Screen Time Do to Children's Brains?Types of IQ: The Quotients Explained (IQ, EQ, SQ, AQ, CQ)What Is the Dunning-Kruger Effect? What the Research Actually ShowsSame Test, Different Patterns: How ADHD and Autism Show Up Differently Across IQ SubtestsGeneral Intelligence vs. Multiple Intelligences: What Each Theory Gets RightNeuroplasticity in Your 30s and 40s: What the Science Actually SaysThe G-Factor vs. Gardner's Multiple Intelligences: What the Evidence Actually ShowsCan Hyperlexia Make You Seem Smarter Than You Actually Are?Is There a Correlation Between IQ and Reaction Time?Can Exercise Affect Your IQ Score?How Does IQ Change as a Person Ages?What Is the Flynn Effect and Why Are IQ Scores Rising?What Part of the Brain Controls IQ and Cognitive Function?Unlocking Your Potential: The Role of Online IQ TestingLogical Reasoning on an IQ Test: How It's Defined, Measured, and Why It Predicts So MuchThe Science Behind IQ Tests: Understanding Intelligence AssessmentExploring the Controversies Surrounding IQ TestsThe Future of IQ Testing: Trends and InnovationsVisual & Spatial Reasoning: What It Is and Why It Shows Up on an IQ TestFluid vs. Crystallized Intelligence: What the Difference Actually MeansIs Everyone About as Smart as I Am???Does Intelligence Research Undermine the Fight against Inequality?Does Intelligence Research Lead to Negative Social Policies?Do Past Controversies Taint Modern Research on Intelligence?Should Controversial or Unpopular Ideas Be Held to a Higher Standard of Evidence?Does Stereotype Threat Explain Score Gaps among Demographic Groups?Do Unique Influences Operate on One Group’s Intelligence Test Scores?Are Racial/Ethnic Group IQ Differences Completely Environmental in Origin?Do Males and Females Have the Same Distribution of IQ Scores?Is Emotional Intelligence a Real Ability that Is Helpful in Life?Is Very High Intelligence More Beneficial than Moderately High Intelligence?Are Intelligence Tests Designed to Create or Perpetuate a False Meritocracy?Is Intelligence Important in the Workplace?Do IQ Scores Just Measure How Good Someone is at Taking Tests?Are Admissions Tests A Barrier to College for Underrepresented Students? Do Non-Cognitive Variables Have Powerful Effects on Academic Achievement?Can Effective Schools Make Every Child Academically Proficient?Is Every Child Gifted?Does Improvability of IQ Mean Intelligence Can Be Equalized?Can Braining-Training Programs Raise IQ?Can Social Interventions Drastically Raise IQ?Are Genes Important for Determining Intelligence?Is Raising IQ Possible?Does IQ Reflect A Person’s Socioeconomic Status?Are Intelligence Tests Biased Against Diverse Populations?Is Practical Intelligence a Real Ability Separate from General Intelligence?Is Intelligence Just A Western Concept?Does IQ Correspond to Brain Anatomy or Functioning?Measuring Cognitive Aging with Memory and Processing Speed TasksComparing Cronbach’s Alpha and McDonald’s Omega ReliabilityWhat is the Flynn Effect? Is the World’s Collective IQ Increasing or Decreasing?How Do You Test Cognitive Functions?Does High IQ Correlate with Success?Creating an IQ TestIncreasing Your IQCulture-Fair Intelligence TestsFlynn EffectCognitive DevelopmentIQ Test QualityDo Non-g Gains from the Flynn Effect Matter?
Take our IQ testsCompare all tests
Basic IQ Test
5 subtests + 5 cognitive abilities
Features
- ~13 Minutes
- IQ score
- Cognitive abilities breakdown
- ±5.6 IQ margin of error
5/15 Subtests
Learn moreVocabulary
Matrix Reasoning
SToVeS
Visual Reversal
Symbol Search
Full IQ Test
15 subtests + all cognitive abilities
Features
- ~52 Minutes
- IQ score
- Cognitive abilities breakdown
- ±3.7 IQ margin of error
15/15 Subtests
Learn moreVocabulary, Information, Analogies
Matrix Reasoning, Visual Puzzles, Figure Weights
Object Rotation, SToVeS, Spatial Orientation
Computation Span, Exposure Memory, Visual Reversal
Symbol Search, Abstract Matching
Simple Reaction Time, Choice Reaction Time
Community
Intelligence Journals & Organizations
Our Articles