Jun 11, 2026·Advanced Topics & Research
Exploring the Controversies Surrounding IQ Tests
Are IQ tests biased or just misunderstood? Explore the truth about stereotype threat, genetics, and test fairness. Read the article and try the RIOT test!
IQ tests are among the most studied and scrutinized instruments in all of psychology. Few other scientific tools have generated as much sustained debate — in academic journals, courtrooms, school board meetings, and public discourse. After more than 15 years researching intelligence and developing the Reasoning and Intelligence Online Test (RIOT), I have thought carefully about these controversies. Most of them are legitimate. Some are based on misunderstandings. Almost none of them justify the conclusion that IQ tests are worthless or should be abandoned.
That last point matters. Engaging honestly with criticism is different from agreeing that the criticized thing should be discarded. A controversy in science is not the same as a refutation. The goal of this article is to examine the major controversies surrounding IQ tests with the same standard of evidence I would apply to any empirical claim — and to reach whatever conclusion that evidence actually supports.
How Did IQ Testing Become Controversial in the First Place?
The history of IQ testing is genuinely troubling in places, and that history helps explain why criticism of IQ tests carries such emotional weight. Alfred Binet, who created the first successful intelligence test in 1905, designed it as a practical tool for identifying children who needed educational support. His explicit position was that the test should not be used to rank children or make sweeping claims about their fixed intellectual potential. That original intent did not survive intact.
By the time IQ testing reached the United States, it had been absorbed into the eugenics movement. Psychologists like Henry Goddard and Lewis Terman promoted the idea that intelligence was a fixed, inherited trait that could be used to sort people — and that society should prevent those deemed "feeble-minded" from reproducing. The consequences were not abstract. In 1927, the U.S. Supreme Court ruled in Buck v. Bell that forced sterilization of people with low IQs was constitutional, resulting in the coerced sterilization of over 65,000 Americans. IQ test data was also used to lobby for the Immigration Act of 1924, which severely restricted entry from Southern and Eastern Europe on the basis of alleged intellectual inferiority of those populations.
These events are real, documented, and shameful. They deserve unambiguous acknowledgment. But they represent the misuse of early IQ tests — and of early science more broadly — by people with ideological agendas who often distorted or ignored what the data actually showed. Modern IQ testing emerged specifically in reaction to these abuses. The ethical and technical standards that now govern test development, the professional oversight bodies, and the mandatory bias screening that has been standard practice since the 1980s all exist in large part because of what went wrong in the first half of the 20th century.
The history of eugenics and IQ testing is a reason to take test misuse seriously. It is not a reason to believe that IQ tests, as they currently exist, are instruments of oppression. Those are different claims.

Are IQ Tests Biased Against Certain Groups?
This is probably the controversy that generates the most heat. The reasoning is intuitive: if certain racial, ethnic, or socioeconomic groups score lower on average than others, the tests must be measuring something other than intelligence — something tied to culture or social disadvantage rather than cognitive ability.
The argument is understandable, but it conflates two distinct concepts that psychologists are careful to keep separate. In technical usage, a test is biased if it produces systematically different predictions for people of equal underlying ability based on group membership — if it underestimates the academic achievement of Black students, for instance, or overpredicts success for white students. Average score differences between groups are not, by themselves, evidence of bias. They can reflect genuine average differences in the abilities being measured, which may have many causes — including environmental ones — that have nothing to do with the test itself.
Since the 1960s, psychologists have developed rigorous statistical methods to test for bias. The consistent finding across decades of research is that professionally developed IQ tests are not biased in this technical sense. They predict academic and occupational outcomes with similar accuracy across racial, ethnic, and gender groups. Items that show differential functioning — meaning they are systematically easier or harder for one group at the same ability level — are identified and removed during development. This process has been standard since the 1980s, and the RIOT underwent the same process.
There is an important distinction, however, between a test being statistically unbiased and a test being fair in a broader sense. An unbiased test is not automatically a fair test. If the abilities the test measures are themselves shaped by unequal access to education, stimulating environments, or other resources, the test may accurately reflect real differences that are themselves the product of social inequality. That is a legitimate concern — but it is a concern about societal conditions, not about the instrument. Blaming a thermometer for recording a fever misidentifies the source of the problem.
Culture-fair tests — nonverbal instruments like the Raven's Progressive Matrices, designed to minimize the role of culturally specific knowledge — were developed in response to these concerns. Research on them has been instructive: they do not eliminate average score differences between groups, and sometimes produce larger gaps than verbal tests. The implication is that what the tests are measuring reflects real differences in cognitive ability development, not just exposure to specific cultural content.
What Is Stereotype Threat, and Does It Explain Score Gaps?
In 1995, social psychologists Claude Steele and Joshua Aronson published an influential study showing that Black college students performed worse on a verbal test when it was described as a measure of intellectual ability than when it was described as a problem-solving exercise. They attributed this to "stereotype threat" — the psychological burden of potentially confirming a negative stereotype about one's group.
The original finding received enormous attention, and for years it was widely reported — including in academic textbooks — as demonstrating that stereotype threat could explain or even eliminate the Black-White gap in cognitive test performance. That interpretation was wrong, and it was corrected in the published literature over a decade ago. A careful reanalysis by Sackett, Hardison, and Cullen (2004) showed that the original Steele and Aronson study had used statistical adjustment for prior SAT scores, which fundamentally changes what the results mean. Without that adjustment, a gap of approximately one standard deviation remained between groups even in the low-threat condition. Steele and Aronson themselves acknowledged this in their published response.
The misinterpretation has persisted despite the correction. A follow-up study in 2022 found that the rate of mischaracterization had dropped from 90.9% to 62.8% in journal articles — still a majority. This is an embarrassing failure of scientific communication.
Does stereotype threat affect test performance at all? The honest answer is: probably a little, under specific conditions. A meta-analysis by Shewach, Sackett, and Quint (2019) examined stereotype threat effects specifically in conditions resembling real high-stakes testing — and found that the effect ranged from negligible to small. The large effects found in laboratory studies largely disappear under realistic testing conditions. Stereotype threat is a real psychological phenomenon with effects in some laboratory contexts, but it is not a major driver of score gaps in operational testing, and it cannot come close to accounting for the group differences observed on large-scale assessments.

How Much of IQ Is Genetic? And Does That Even Matter?
The heritability of intelligence is probably the most politically charged topic in all of psychology. Heritability refers to the proportion of variation in a trait within a population that is attributable to genetic differences between individuals. In adults in wealthy, non-neglectful environments, the heritability of IQ ranges from approximately 50% to 80%. This is one of the most replicated findings in behavioral genetics.
Three persistent misconceptions cloud this discussion. First, heritability does not mean "caused by genes" in a fixed or deterministic sense. A heritability of 70% does not mean that 70% of any individual's IQ is determined by their genes. It means that 70% of the variation between people in that population can be attributed to genetic differences, given the range of environments studied. Height has a heritability of approximately 90% in wealthy countries — yet average height has increased by several inches across generations due to better nutrition. High heritability and environmental malleability are completely compatible.
Second, heritability is not a fixed property of a trait. It depends on the range of environments being studied. In populations where environments are highly uniform, heritability goes up — because genetic variation accounts for more of the remaining differences. In populations with wide environmental variation, including deprivation, heritability can be substantially lower. Studies of low-income families in the United States have found heritability estimates for IQ near zero in early childhood, with shared environment accounting for most of the variance instead. This finding has important policy implications: it suggests that improving environments — especially early in life — can matter enormously for cognitive development.
Third, and most importantly, heritability tells us nothing about the causes of average differences between groups. Even if IQ were highly heritable within both Black and white populations in the United States, that would not imply that the average score difference between those groups has a genetic cause. The logic does not follow. Two fields of the same crop variety can both show high heritability for plant height — with genes explaining most of the height differences within each field — while the difference in average height between the two fields is entirely due to differences in soil, sunlight, and water. Within-group heritability says nothing about between-group differences.
The scientific consensus today is that observed average IQ differences between racial groups in the United States are not attributable to genetic differences between those groups. The evidence for environmental causes — including education, socioeconomic resources, exposure to toxins like lead, and nutrition — is far better supported.
Does IQ Capture Everything That Matters Cognitively?
A recurring criticism is that IQ tests are too narrow — that they measure only a slice of human ability and leave out creativity, social skill, practical competence, and other traits that matter in real life. This criticism has some truth to it, and I want to be clear about that.
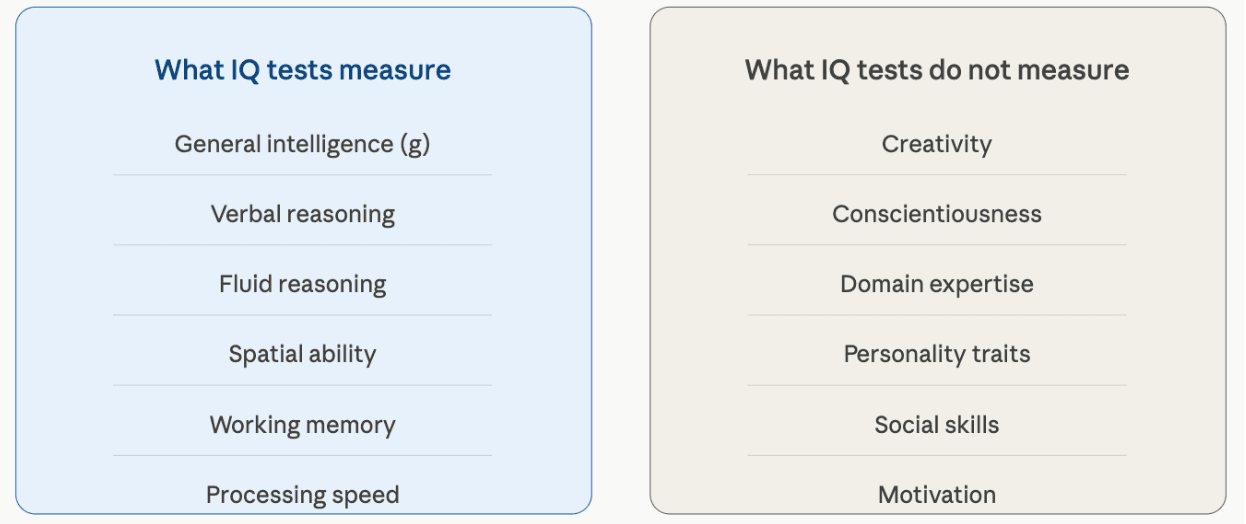
IQ tests measure general cognitive ability, or g, along with a set of more specific cognitive abilities such as verbal reasoning, fluid reasoning, processing speed, and working memory. They do not measure creativity, personality, motivation, specific domain expertise, or the countless narrow skills that matter in particular fields. No professional in intelligence research claims otherwise. Tests like the RIOT are designed to measure what they are designed to measure — and technical documentation is explicit about what those intended uses are and are not.
The legitimate question is whether what IQ tests do measure matters in the real world. The answer is yes, substantially and consistently. General cognitive ability is among the strongest known predictors of academic achievement, job performance across nearly all occupations, income, health outcomes, and longevity. These relationships hold even after controlling for many other variables. That does not make IQ a complete portrait of a person, and it does not justify treating a score as someone's defining characteristic. But it does mean that the measurement is capturing something real and consequential.
The more interesting version of this critique is whether what IQ tests miss is large enough to undermine their predictive value. For most purposes where cognitive assessment is relevant — clinical diagnosis, educational placement, occupational selection — the answer from decades of research is that other non-cognitive predictors add value at the margins. Conscientiousness, for example, adds modest predictive validity for job performance beyond IQ. But no non-cognitive measure comes close to replacing general intelligence as a predictor.
Is a Single Number Too Reductive?
A softer version of the narrowness critique is the objection to expressing intelligence as a single IQ score. Human cognition is rich and multidimensional — isn't it misleading to collapse it into one number?
The objection has merit as a critique of how scores are sometimes communicated, but less merit as a critique of the tests themselves. Modern IQ test batteries, including the RIOT, do not report only a single overall score. They report a global IQ alongside index scores that capture different domains — in the RIOT's case, Verbal Reasoning, Fluid Reasoning, Spatial Ability, Working Memory, Processing Speed, and Reaction Time. The overall score reflects the robust finding that performance across cognitive domains is correlated (the g factor), while the subscores capture the meaningful variation that exists within that overall picture.
The debate over g itself is worth noting. Spearman's discovery that performance across diverse cognitive tests correlates consistently — that people who do well on one test tend to do relatively well on others — is one of the most replicated findings in psychology. Whether g represents a single underlying biological entity or is better understood as an emergent statistical pattern remains debated, but the practical reality of the positive manifold is not seriously in dispute among researchers.
The reductiveness objection is most valid when a score is used as if it defines a person's potential ceiling rather than describes their current standing relative to peers. That misuse is real and worth preventing. It does not, however, imply that summary scores are inherently misleading — only that they require accurate interpretation.

What the Controversies Actually Tell Us
Working through these controversies honestly produces a consistent pattern. In each case, the criticism points to something real — historical abuses, the existence of group score gaps, the limits of what tests measure — but the evidence does not support the stronger conclusion that IQ tests as currently developed are unreliable, unfair, or without value. The scrutiny has, in most cases, made the field better: bias-screening methods improved, the stereotype threat literature was corrected, and heritability research has grown more sophisticated in distinguishing within-group from between-group inference.
A score from a professionally developed IQ test is a snapshot of a person's cognitive performance relative to their age group. It is not a measure of worth, potential, or destiny. Used well, it provides genuinely useful information. Used carelessly or maliciously, like any powerful scientific tool, it can cause harm. The lesson of the controversies is not that measurement is dangerous — it is that the people doing the measuring bear serious responsibility for how they use what they find.
Take the First Professional Online IQ Test
The Reasoning and Intelligence Online Test (RIOT) was developed with all of the concerns discussed in this article in mind. Its items were reviewed by a panel of diverse experts from cognitive, educational, and developmental psychology and screened for differential item functioning before release. It was normed on a representative U.S. adult sample and meets all relevant standards from the Standards for Educational and Psychological Testing established by the American Educational Research Association, American Psychological Association, and National Council on Measurement in Education. Its technical documentation is publicly available, and its creator's credentials are transparent.
The RIOT reports both a global IQ and domain-level index scores — so the measurement is not collapsed into a single number without context. For anyone who wants an accurate picture of their cognitive abilities from a professionally developed, ethically constructed instrument, it represents what responsible online intelligence testing can look like.
Sources
- Steele, C. M., & Aronson, J. (1995). Stereotype threat and the intellectual test performance of African Americans. Journal of Personality and Social Psychology, 69(5), 797–811. https://doi.org/10.1037/0022-3514.69.5.797
- Sackett, P. R., Hardison, C. M., & Cullen, M. J. (2004). On interpreting stereotype threat as accounting for African American-White differences on cognitive tests. American Psychologist, 59(1), 7–13. https://doi.org/10.1037/0003-066X.59.1.7
- Shewach, O. R., Sackett, P. R., & Quint, S. (2019). Stereotype threat effects in settings with features likely versus unlikely in operational test settings: A meta-analysis. Journal of Applied Psychology, 104(12), 1514–1534. https://doi.org/10.1037/apl0000420
- Tomeh, D. H., & Sackett, P. R. (2022). On the continued misinterpretation of stereotype threat as accounting for Black-White differences on cognitive tests. Personnel Assessment and Decisions, 8(1). https://scholarworks.bgsu.edu/pad/vol8/iss1/1
- Plomin, R., & Deary, I. J. (2015). Genetics and intelligence differences: five special findings. Molecular Psychiatry, 20(1), 98–108. https://doi.org/10.1038/mp.2014.105
- Turkheimer, E., Haley, A., Waldron, M., D'Onofrio, B., & Gottesman, I. I. (2003). Socioeconomic status modifies heritability of IQ in young children. Psychological Science, 14(6), 623–628. https://doi.org/10.1046/j.0956-7976.2003.psci_1475.x
- Warne, R. T. (2020). In the know: Debunking 35 myths about human intelligence. Cambridge University Press. https://doi.org/10.1017/9781108593298
- Gottfredson, L. S. (1997). Mainstream science on intelligence. Intelligence, 24(1), 13–23. https://doi.org/10.1016/S0160-2896(97)90011-8
- Martschenko, D. (2017). The IQ test wars: Why screening for intelligence is still so controversial. The Conversation. https://theconversation.com/the-iq-test-wars-why-screening-for-intelligence-is-still-so-controversial-81428
- Holden, L. R., & Tanenbaum, G. J. (2023). Modern assessments of intelligence must be fair and equitable. Journal of Intelligence, 11(6), 126. https://doi.org/10.3390/jintelligence11060126
- Reddy, A. (2008). The eugenic origins of IQ testing: Implications for post-Atkins litigation. DePaul Law Review, 57. https://via.library.depaul.edu/law-review
- Warne, R. T. (2025). Technical manual for the Reasoning and Intelligence Online Test, version 1.0. Riot IQ.
- American Educational Research Association, American Psychological Association, & National Council on Measurement in Education. (2014). Standards for educational and psychological testing. https://www.testingstandards.net
- Riotiq.com. (2025). Are IQ tests biased? https://www.riotiq.com/articles/accuracy-reliability-and-criticism/are-iq-tests-biased
- Breit, M., et al. (2024). Stability of intelligence across the lifespan. Intelligence. https://doi.org/10.1016/j.intell.2024.101871
Take our professional IQ test
Want to know your IQ? Try the first ever professional online IQ test.
Article Categories
All ArticlesUnderstanding IQ ScoresTaking an IQ TestRIOT-Specific InformationGeneral IQ & IntelligenceAdvanced Topics & ResearchIQ Scores & InterpretationMensa & High-IQ SocietiesOnline IQ Tests IQ Test Basics & FundamentalsAverage IQ & DemographicsFamous People & IQHistory & Origins Of IQ TestingAccuracy, Reliability & CriticismSpecial Population & Related ConditionsImproving IQ / PreparationSpecific IQ Tests & FormatsIQ Testing for HR & RecruitmentSkills Assessment
Related Articles
Does High IQ Actually Correlate With Higher Salary After Age 30?High IQ vs. High EQ: Which One Predicts Long-Term Relationship Happiness?Are You Left-Brained or Right-Brained? What Neuroscience Actually SaysWhat Does Too Much Screen Time Do to Children's Brains?Types of IQ: The Quotients Explained (IQ, EQ, SQ, AQ, CQ)What Is the Dunning-Kruger Effect? What the Research Actually ShowsSame Test, Different Patterns: How ADHD and Autism Show Up Differently Across IQ SubtestsGeneral Intelligence vs. Multiple Intelligences: What Each Theory Gets RightNeuroplasticity in Your 30s and 40s: What the Science Actually SaysThe G-Factor vs. Gardner's Multiple Intelligences: What the Evidence Actually ShowsCan Hyperlexia Make You Seem Smarter Than You Actually Are?Is There a Correlation Between IQ and Reaction Time?Can Exercise Affect Your IQ Score?How Does IQ Change as a Person Ages?What Is the Flynn Effect and Why Are IQ Scores Rising?What Part of the Brain Controls IQ and Cognitive Function?Unlocking Your Potential: The Role of Online IQ TestingLogical Reasoning on an IQ Test: How It's Defined, Measured, and Why It Predicts So MuchThe Science Behind IQ Tests: Understanding Intelligence AssessmentExploring the Controversies Surrounding IQ TestsThe Future of IQ Testing: Trends and InnovationsVisual & Spatial Reasoning: What It Is and Why It Shows Up on an IQ TestFluid vs. Crystallized Intelligence: What the Difference Actually MeansIs Everyone About as Smart as I Am???Does Intelligence Research Undermine the Fight against Inequality?Does Intelligence Research Lead to Negative Social Policies?Do Past Controversies Taint Modern Research on Intelligence?Should Controversial or Unpopular Ideas Be Held to a Higher Standard of Evidence?Does Stereotype Threat Explain Score Gaps among Demographic Groups?Do Unique Influences Operate on One Group’s Intelligence Test Scores?Are Racial/Ethnic Group IQ Differences Completely Environmental in Origin?Do Males and Females Have the Same Distribution of IQ Scores?Is Emotional Intelligence a Real Ability that Is Helpful in Life?Is Very High Intelligence More Beneficial than Moderately High Intelligence?Are Intelligence Tests Designed to Create or Perpetuate a False Meritocracy?Is Intelligence Important in the Workplace?Do IQ Scores Just Measure How Good Someone is at Taking Tests?Are Admissions Tests A Barrier to College for Underrepresented Students? Do Non-Cognitive Variables Have Powerful Effects on Academic Achievement?Can Effective Schools Make Every Child Academically Proficient?Is Every Child Gifted?Does Improvability of IQ Mean Intelligence Can Be Equalized?Can Braining-Training Programs Raise IQ?Can Social Interventions Drastically Raise IQ?Are Genes Important for Determining Intelligence?Is Raising IQ Possible?Does IQ Reflect A Person’s Socioeconomic Status?Are Intelligence Tests Biased Against Diverse Populations?Is Practical Intelligence a Real Ability Separate from General Intelligence?Is Intelligence Just A Western Concept?Does IQ Correspond to Brain Anatomy or Functioning?Measuring Cognitive Aging with Memory and Processing Speed TasksComparing Cronbach’s Alpha and McDonald’s Omega ReliabilityWhat is the Flynn Effect? Is the World’s Collective IQ Increasing or Decreasing?How Do You Test Cognitive Functions?Does High IQ Correlate with Success?Creating an IQ TestIncreasing Your IQCulture-Fair Intelligence TestsFlynn EffectCognitive DevelopmentIQ Test QualityDo Non-g Gains from the Flynn Effect Matter?
Take our IQ testsCompare all tests
Basic IQ Test
5 subtests + 5 cognitive abilities
Features
- ~13 Minutes
- IQ score
- Cognitive abilities breakdown
- ±5.6 IQ margin of error
5/15 Subtests
Learn moreVocabulary
Matrix Reasoning
SToVeS
Visual Reversal
Symbol Search
Full IQ Test
15 subtests + all cognitive abilities
Features
- ~52 Minutes
- IQ score
- Cognitive abilities breakdown
- ±3.7 IQ margin of error
15/15 Subtests
Learn moreVocabulary, Information, Analogies
Matrix Reasoning, Visual Puzzles, Figure Weights
Object Rotation, SToVeS, Spatial Orientation
Computation Span, Exposure Memory, Visual Reversal
Symbol Search, Abstract Matching
Simple Reaction Time, Choice Reaction Time
Community
Intelligence Journals & Organizations
Our Articles